
Author: 0xjacobzhao and ChatGPT 4o
1. Introduction | Crypto AI’s Model-Level Transition
Data, models and computing power are the three core elements of AI infrastructure, just like fuel (data), engines (models), and energy (computing power). Similar to the infrastructure evolution path of the traditional AI industry, the Crypto AI field has also gone through similar stages. At the beginning of 2024, the market was once dominated by decentralized GPU projects (Akash, Render, io.net, etc.), which generally emphasized the extensive growth logic of "competing for computing power". After entering 2025, the industry's focus has gradually shifted to the model and data layer, indicating that Crypto AI is transitioning from underlying resource competition to more sustainable and application-valuable middle-level construction.
Large General Model (LLM) vs Specialized Model (SLM)
Traditional large language model (LLM) training is highly dependent on large-scale data sets and complex distributed architectures, with parameter sizes ranging from 70B to 500B, and the cost of training is often as high as millions of dollars. As a lightweight fine-tuning paradigm for reusable basic models, SLM (Specialized Language Model) is usually based on open source models such as LLaMA, Mistral, and DeepSeek, combined with a small amount of high-quality professional data and technologies such as LoRA, to quickly build expert models with specific domain knowledge, significantly reducing training costs and technical barriers.
It is worth noting that SLM will not be integrated into the LLM weight, but will work in collaboration with LLM through Agent architecture calls, plug-in system dynamic routing, LoRA module hot swapping, RAG (retrieval enhancement generation), etc. This architecture not only retains the wide coverage capability of LLM, but also enhances professional performance through fine-tuning modules, forming a highly flexible combined intelligent system.
The value and boundaries of Crypto AI at the model level
Crypto AI projects are inherently difficult to directly improve the core capabilities of large language models (LLMs). The core reason is that
- The technical threshold is too high: The data scale, computing resources and engineering capabilities required to train the Foundation Model are extremely large. Currently, only technology giants such as the United States (OpenAI, etc.) and China (DeepSeek, etc.) have the corresponding capabilities.
- Limitations of the open source ecosystem: Although mainstream basic models such as LLaMA and Mixtral have been open source, the key to truly promoting model breakthroughs is still concentrated in scientific research institutions and closed-source engineering systems, and on-chain projects have limited room for participation in the core model layer.
However, based on the open source basic model, Crypto AI projects can still achieve value extension by fine-tuning the specialized language model (SLM) and combining the verifiability and incentive mechanism of Web3. As the "peripheral interface layer" of the AI industry chain, it is reflected in two core directions:
- Trusted Verification Layer: Enhances the traceability and tamper-resistance of AI output by recording model generation paths, data contributions, and usage on the chain.
- Incentive mechanism: With the help of native tokens, it is used to incentivize behaviors such as data uploading, model calling, and agent execution to build a positive cycle of model training and service.
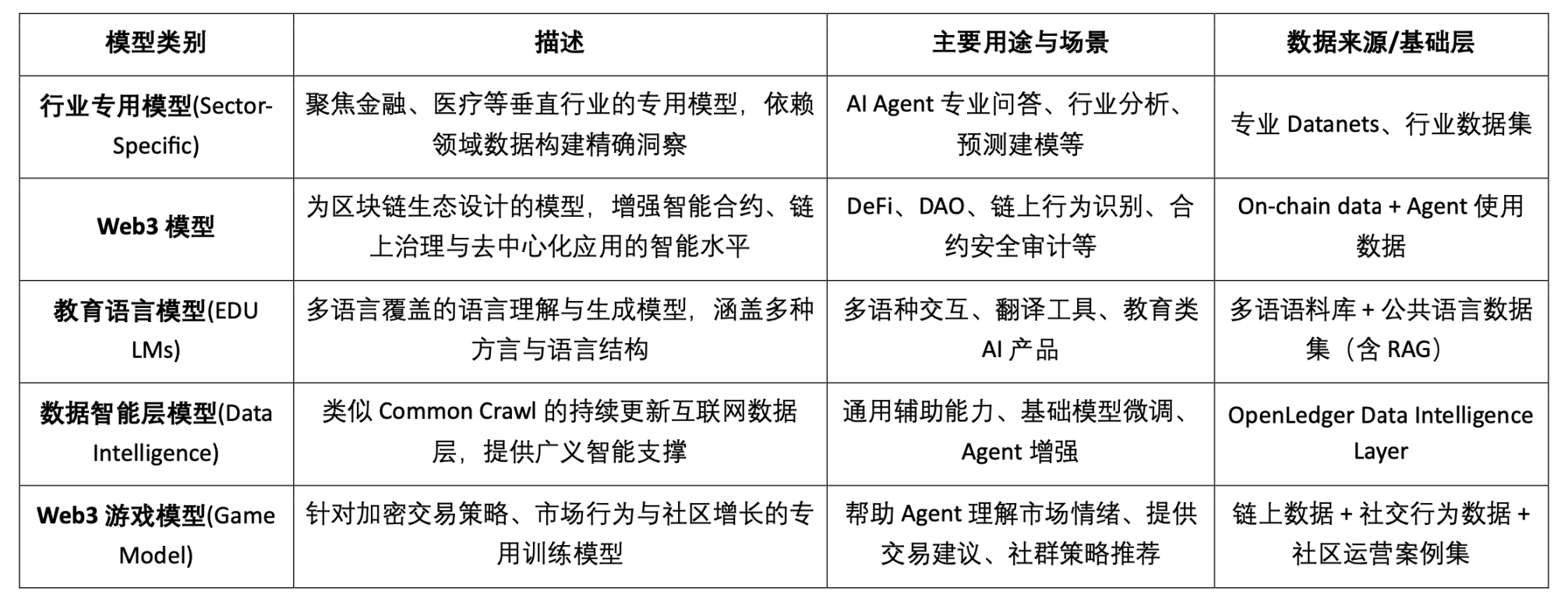
AI model type classification and blockchain applicability analysis
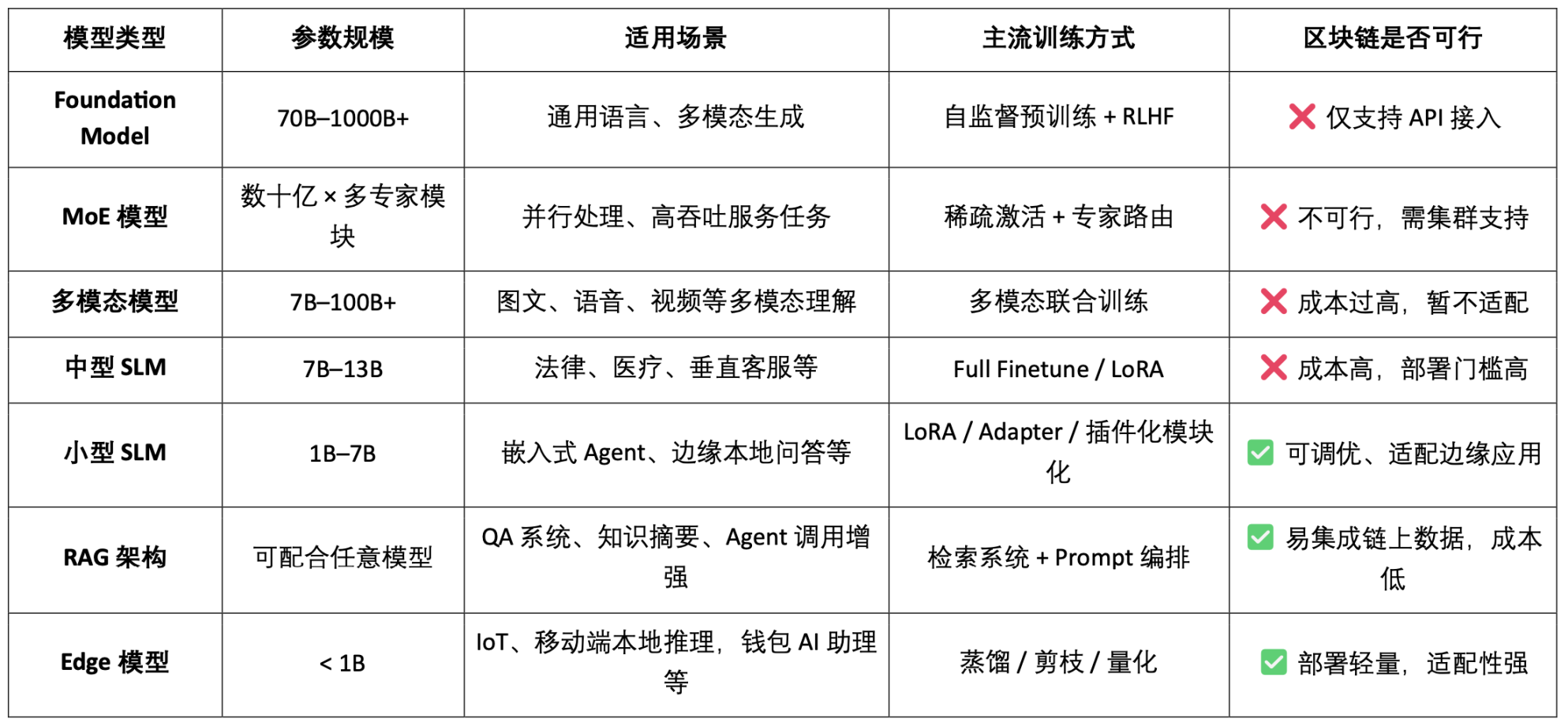
It can be seen that the feasible landing points of model-based Crypto AI projects are mainly concentrated on the lightweight fine-tuning of small SLMs, on-chain data access and verification of RAG architecture, and local deployment and incentives of Edge models. Combined with the verifiability of blockchain and the token mechanism, Crypto can provide unique value for these low- and medium-resource model scenarios, forming the differentiated value of the AI "interface layer".
The blockchain AI chain based on data and models can record the contribution source of each piece of data and model clearly and in an unalterable way, significantly improving the credibility of data and the traceability of model training. At the same time, through the smart contract mechanism, rewards are automatically distributed when data or models are called, converting AI behaviors into measurable and tradable tokenized values, and building a sustainable incentive system. In addition, community users can also evaluate model performance, participate in rule-making and iteration through token voting, and improve the decentralized governance architecture.
2. Project Overview | OpenLedger’s AI Chain Vision
OpenLedger is one of the few blockchain AI projects in the market that focuses on data and model incentive mechanisms. It was the first to propose the concept of "Payable AI", aiming to build a fair, transparent and composable AI operating environment, incentivizing data contributors, model developers and AI application builders to collaborate on the same platform and obtain on-chain benefits based on actual contributions.
OpenLedger provides a full chain closed loop from "data provision" to "model deployment" to "call profit sharing". Its core modules include:
- Model Factory: fine-tune, train and deploy custom models using LoRA based on open source LLM without programming;
- OpenLoRA: supports the coexistence of thousands of models and dynamic loading on demand, significantly reducing deployment costs;
- PoA (Proof of Attribution): Contribution measurement and reward distribution are achieved through on-chain call records;
- Datanets: structured data networks for vertical scenarios, built and verified by community collaboration;
- Model Proposal Platform: A composable, callable, and payable on-chain model market.
Through the above modules, OpenLedger has built a data-driven, model-composable "intelligent economic infrastructure" to promote the on-chainization of the AI value chain.
In terms of blockchain technology adoption, OpenLedger uses OP Stack + EigenDA as the foundation to build a high-performance, low-cost, and verifiable data and contract operating environment for AI models.
- Built on OP Stack: Based on the Optimism technology stack, it supports high throughput and low-cost execution;
- Settlement on the Ethereum mainnet: ensuring transaction security and asset integrity;
- EVM compatibility: It facilitates developers to quickly deploy and expand based on Solidity;
- EigenDA provides data availability support: significantly reducing storage costs and ensuring data verifiability.
Compared to general AI chains such as NEAR, which are more low-level and focus on data sovereignty and "AI Agents on BOS" architecture, OpenLedger is more focused on building AI-specific chains for data and model incentives, and is committed to making model development and calls traceable, composable and sustainable on-chain value closed loops. It is the model incentive infrastructure in the Web3 world, combining HuggingFace-style model hosting, Stripe-style usage billing and Infura-style on-chain composable interfaces to promote the realization path of "model as asset".
3. OpenLedger’s core components and technical architecture
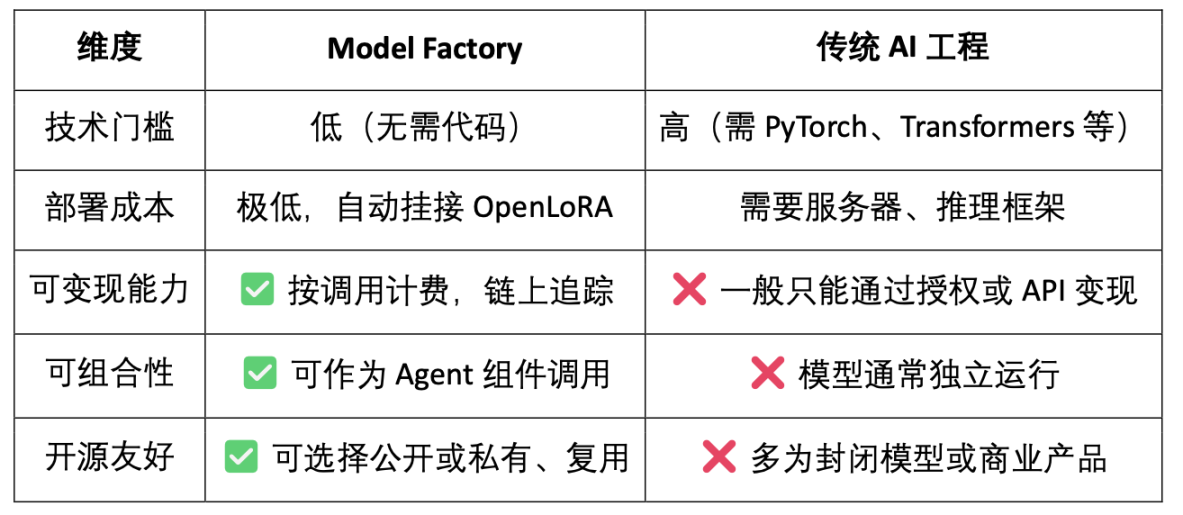
3.1 Model Factory, no code required Model Factory
ModelFactory is a large language model (LLM) fine-tuning platform under the OpenLedger ecosystem. Unlike traditional fine-tuning frameworks, ModelFactory provides pure graphical interface operations without the need for command line tools or API integration. Users can fine-tune models based on datasets that have been authorized and reviewed on OpenLedger. It implements an integrated workflow for data authorization, model training, and deployment. Its core processes include:
- Data access control: Users submit data requests, providers review and approve them, and data is automatically connected to the model training interface.
- Model selection and configuration: Supports mainstream LLMs (such as LLaMA, Mistral), and configures hyperparameters through the GUI.
- Lightweight fine-tuning: Built-in LoRA / QLoRA engine, real-time display of training progress.
- Model evaluation and deployment: Built-in evaluation tools support export deployment or ecological sharing calls.
- Interactive verification interface: Provides a chat-style interface for direct testing of the model's question-and-answer capabilities.
- RAG generates provenance: Answers are accompanied by source references, enhancing trust and auditability.
The Model Factory system architecture consists of six major modules, covering identity authentication, data permissions, model fine-tuning, evaluation deployment and RAG traceability, to create an integrated model service platform that is secure, controllable, real-time interactive and sustainable.
The following table summarizes the large language model capabilities currently supported by ModelFactory:
- LLaMA series: has the broadest ecosystem, active community, and strong general performance. It is one of the most mainstream open source basic models.
- Mistral: With efficient architecture and excellent inference performance, it is suitable for scenarios with flexible deployment and limited resources.
- Qwen: Produced by Alibaba, it performs well in Chinese tasks and has strong comprehensive capabilities, making it the first choice for domestic developers.
- ChatGLM: It has outstanding Chinese conversation effects and is suitable for vertical customer service and localization scenarios.
- Deepseek: It excels in code generation and mathematical reasoning and is suitable for intelligent development assistance tools.
- Gemma: A lightweight model launched by Google with a clear structure that is easy to get started and experiment with quickly.
- Falcon: Once a performance benchmark, suitable for basic research or comparative testing, but the community activity has declined.
- BLOOM: It has strong multi-language support but weak reasoning performance, and is suitable for language coverage research.
- GPT-2: A classic early model, suitable only for teaching and verification purposes, and not recommended for actual deployment.
Although OpenLedger's model portfolio does not include the latest high-performance MoE models or multimodal models, its strategy is not outdated. Instead, it is a "practical first" configuration based on the realistic constraints of on-chain deployment (inference cost, RAG adaptation, LoRA compatibility, EVM environment).
As a code-free tool chain, Model Factory has a built-in contribution proof mechanism for all models to ensure the rights and interests of data contributors and model developers. It has the advantages of low threshold, monetization and composability. Compared with traditional model development tools:
- For developers: Provide a complete path for model incubation, distribution, and revenue;
- For the platform: forming a model asset circulation and combination ecosystem;
- For users: You can combine and use models or agents just like calling APIs.
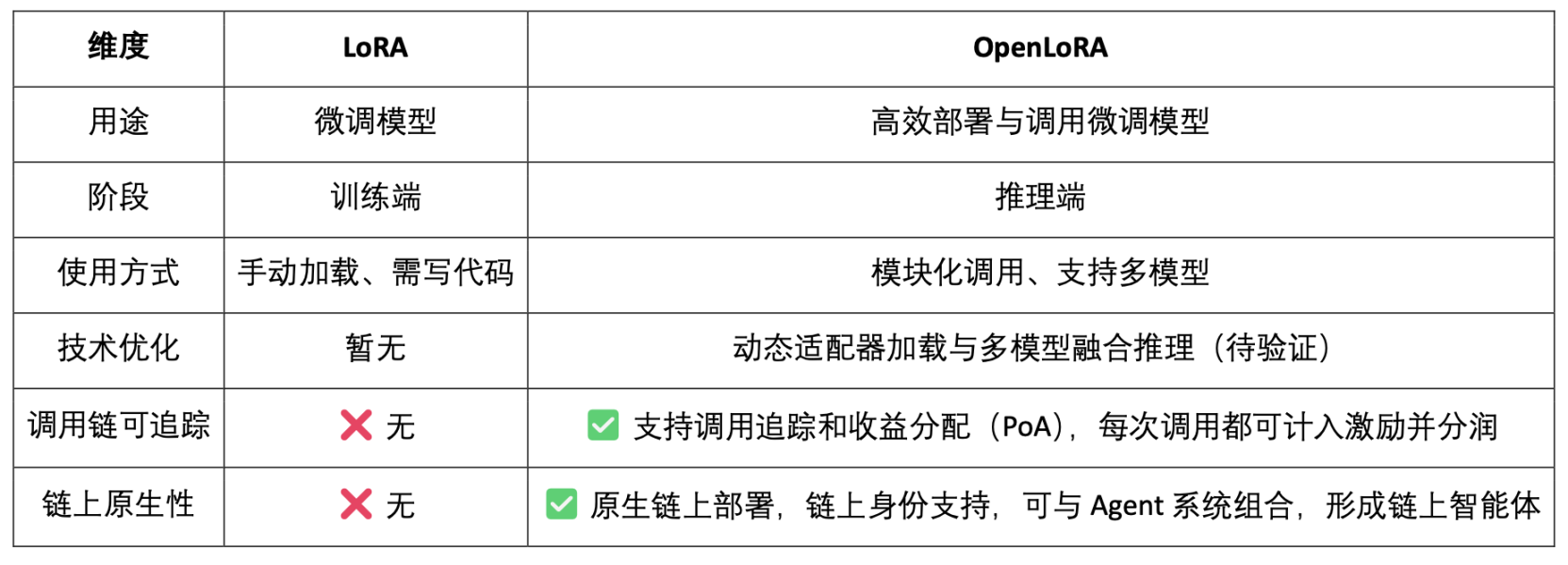
3.2 OpenLoRA, fine-tuning the model on-chain assetization
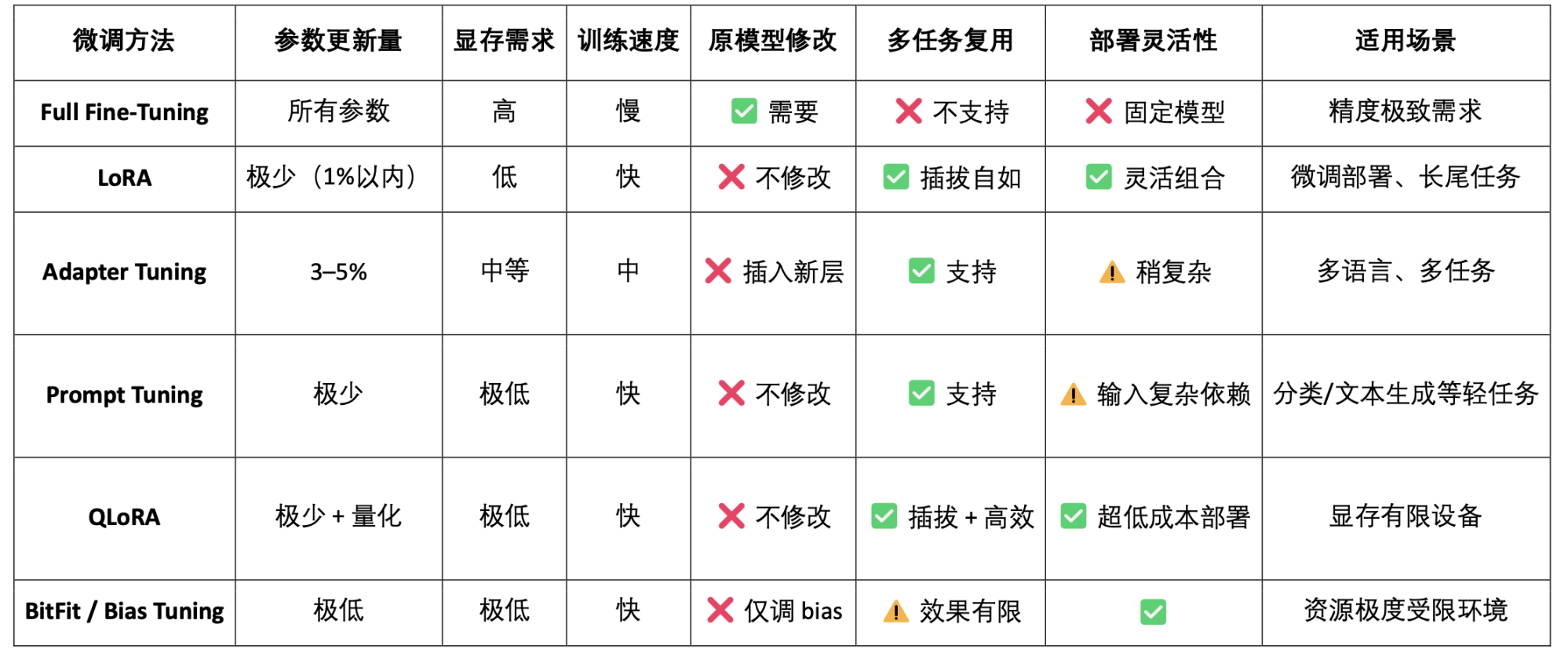
LoRA (Low-Rank Adaptation) is an efficient parameter fine-tuning method that learns new tasks by inserting "low-rank matrices" into pre-trained large models without modifying the original model parameters, thereby significantly reducing training costs and storage requirements. Traditional large language models (such as LLaMA, GPT-3) usually have billions or even hundreds of billions of parameters. To use them for specific tasks (such as legal question-answering, medical consultation), fine-tuning is required. The core strategy of LoRA is: "Freeze the parameters of the original large model and only train the inserted new parameter matrix." Its parameters are efficient, training is fast, and deployment is flexible. It is currently the most suitable mainstream fine-tuning method for Web3 model deployment and combined calls.
OpenLoRA is a lightweight inference framework built by OpenLedger specifically for multi-model deployment and resource sharing. Its core goal is to solve the common problems of high cost, low reuse, and GPU resource waste in current AI model deployment, and promote the implementation of "Payable AI".
The core components of the OpenLoRA system architecture are based on modular design, covering key links such as model storage, reasoning execution, and request routing, to achieve efficient and low-cost multi-model deployment and calling capabilities:
- LoRA Adapter Storage Module: The fine-tuned LoRA adapter is hosted on OpenLedger to achieve on-demand loading, avoiding pre-loading all models into the video memory and saving resources.
- Model Hosting & Adapter Merging Layer: All fine-tuned models share the base model. During inference, LoRA adapters are dynamically merged to support ensemble inference of multiple adapters to improve performance.
- Inference Engine: Integrates multiple CUDA optimization technologies such as Flash-Attention, Paged-Attention, and SGMV optimization.
- Request Router & Token Streaming: Dynamically routes requests to the correct adapter based on the model required in the request, and implements token-level streaming generation by optimizing the kernel.
The reasoning process of OpenLoRA belongs to the "mature and universal" model service process at the technical level, as follows:
- Basic model loading: The system preloads basic large models such as LLaMA 3 and Mistral into the GPU memory.
- LoRA dynamic retrieval: After receiving a request, dynamically load the specified LoRA adapter from Hugging Face, Predibase or local directory.
- Adapter merging activation: The adapter is merged with the base model in real time by optimizing the kernel, supporting multi-adapter combined reasoning.
- Inference execution and streaming output: The merged model starts to generate responses, using token-level streaming output to reduce latency, and combining quantization to ensure efficiency and accuracy.
- End of inference and release of resources: After inference is completed, the adapter is automatically uninstalled to release video memory resources. This ensures that thousands of fine-tuned models can be efficiently rotated and served on a single GPU, supporting efficient model rotation.
OpenLoRA has significantly improved the efficiency of multi-model deployment and reasoning through a series of underlying optimization methods. Its core includes dynamic LoRA adapter loading (JIT loading), which effectively reduces video memory usage; Tensor Parallelism and Paged Attention achieve high concurrency and long text processing; support multi-model fusion (Multi-Adapter Merging) multi-adapter merge execution to achieve LoRA combined reasoning (ensemble); at the same time, through Flash Attention, pre-compiled CUDA kernels and FP8/INT8 quantization technology, the underlying CUDA optimization and quantization support further improves the reasoning speed and reduces latency. These optimizations enable OpenLoRA to efficiently serve thousands of fine-tuned models in a single-card environment, taking into account performance, scalability and resource utilization.
OpenLoRA is positioned not only as an efficient LoRA reasoning framework, but also as a deep integration of model reasoning and Web3 incentive mechanism. Its goal is to turn the LoRA model into a callable, composable, and divisible Web3 asset.
- Model-as-Asset: OpenLoRA not only deploys models, but also gives each fine-tuned model an on-chain identity (Model ID) and binds its calling behavior with economic incentives to achieve "calling is profit sharing".
- Dynamic merging of multiple LoRAs + profit sharing: supports dynamic combination calls of multiple LoRA adapters, allowing different models to be combined to form new Agent services. At the same time, the system can accurately distribute profits to each adapter based on the call volume based on the PoA (Proof of Attribution) mechanism.
- Supports "multi-tenant shared inference" for long-tail models: Through dynamic loading and memory release mechanisms, OpenLoRA can serve thousands of LoRA models in a single-card environment, which is particularly suitable for high-reuse, low-frequency calling scenarios such as niche models in Web3 and personalized AI assistants.
In addition, OpenLedger released its future outlook for OpenLoRA performance indicators. Compared with the traditional full-parameter model deployment, its memory usage is greatly reduced to 8-12GB; the model switching time can theoretically be less than 100ms; the throughput can reach 2000+ tokens/sec; and the delay is controlled at 20-50ms. Overall, these performance indicators are technically accessible, but closer to the "upper limit performance". In actual production environments, performance may be limited by hardware, scheduling strategies, and scene complexity, and should be regarded as "ideal upper limit" rather than "stable daily".
3.3 Datanets: From Data Sovereignty to Data Intelligence
High-quality, domain-specific data has become a key element in building high-performance models. Datanets is the infrastructure of OpenLedger's "data as an asset", which is used to collect and manage data sets in specific fields. It is a decentralized network for aggregating, verifying and distributing data in specific fields, providing high-quality data sources for the training and fine-tuning of AI models. Each Datanet is like a structured data warehouse, where contributors upload data and ensure that the data is traceable and trustworthy through an on-chain attribution mechanism. Through incentive mechanisms and transparent permission control, Datanets realizes the community co-construction and trusted use of data required for model training.
Compared with projects such as Vana that focus on data sovereignty, OpenLedger is not limited to "data collection", but extends the value of data to model training and on-chain calls through three modules: Datanets (collaboratively labeled and attributed data sets), Model Factory (model training tools that support code-free fine-tuning), and OpenLoRA (traceable and composable model adapters), building a complete closed loop from "data to intelligence". Vana emphasizes "who owns the data", while OpenLedger focuses on "how data is trained, called and rewarded", occupying key positions in data sovereignty protection and data monetization paths in the Web3 AI ecosystem.
3.4 Proof of Attribution: Reshaping the incentive layer for benefit distribution
Proof of Attribution (PoA) is the core mechanism of OpenLedger to achieve data ownership and incentive distribution. Through on-chain encrypted records, each piece of training data is verifiably associated with the model output to ensure that contributors receive the rewards they deserve in model calls. The data ownership and incentive process is outlined as follows:
- Data submission: Users upload structured, domain-specific data sets and confirm ownership on the chain.
- Impact Assessment: The system evaluates the value of each inference based on the impact of data features and the reputation of contributors.
- Training verification: The training log records the actual usage of each piece of data to ensure that the contribution is verifiable.
- Incentive distribution: Based on the influence of the data, contributors will be awarded token rewards linked to the results.
- Quality governance: Penalize low-quality, redundant, or malicious data to ensure the quality of model training.
Compared with the Bittensor subnet architecture combined with the scoring mechanism of the blockchain universal incentive network, OpenLedger focuses on the value capture and profit sharing mechanism at the model level. PoA is not only an incentive distribution tool, but also a framework for transparency, source tracking and multi-stage attribution: it records the entire process of data upload, model call, and intelligent agent execution on the chain to achieve an end-to-end verifiable value path. This mechanism allows each model call to be traced back to the data contributor and model developer, thereby achieving true "value consensus" and "revenue" in the on-chain AI system.
RAG (Retrieval-Augmented Generation) is an AI architecture that combines a retrieval system with a generative model. It aims to solve the problems of "closed knowledge" and "fabrication" in traditional language models. It enhances the model generation capability by introducing an external knowledge base, making the output more realistic, explainable, and verifiable. RAG Attribution is a data attribution and incentive mechanism established by OpenLedger in the Retrieval-Augmented Generation scenario. It ensures that the content of the model output is traceable and verifiable, and that contributors can be incentivized, ultimately achieving trustworthy generation and data transparency. The process includes:
- User asks a question → retrieves data: After receiving the question, the AI retrieves relevant content from the OpenLedger data index.
- Data is called and answers are generated: The retrieved content is used to generate model answers, and the calling behavior is recorded on the chain.
- Contributors are rewarded: After the data is used, its contributors receive incentives calculated based on the amount and relevance.
- Generate results with citations: Model output comes with links to original data sources, enabling transparent Q&A and verifiable content.

OpenLedger's RAG Attribution allows every AI answer to be traced back to the real data source, and contributors are rewarded according to the frequency of citations, realizing "knowledge has a source and can be monetized when called." This mechanism not only improves the transparency of model output, but also builds a sustainable incentive closed loop for high-quality data contributions, and is a key infrastructure for promoting trusted AI and data assetization.
4. OpenLedger Project Progress and Ecosystem Cooperation
Currently, OpenLedger has launched the test network. The Data Intelligence Layer is the first stage of the OpenLedger test network, which aims to build an Internet data warehouse jointly driven by community nodes. These data are screened, enhanced, classified and structured to eventually form auxiliary intelligence suitable for large language models (LLMs) for building domain AI models on OpenLedger. Community members can run edge device nodes to participate in data collection and processing. Nodes will use local computing resources to perform data-related tasks, and participants will receive points based on their activity and task completion. These points will be converted into OPEN tokens in the future, and the specific exchange ratio will be announced before the token generation event (TGE).
The OpenLedger testnet currently provides the following three types of revenue mechanisms:
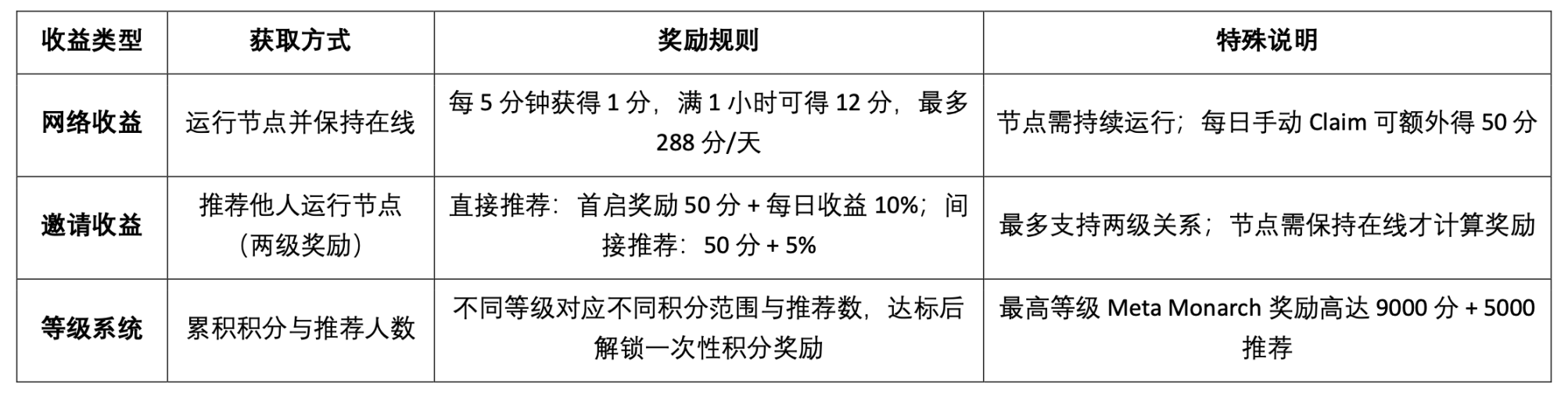
The Epoch 2 testnet focuses on launching the Datanets data network mechanism. This stage is limited to whitelisted users, and they need to complete the pre-assessment to unlock the task. The tasks include data verification, classification, etc. After completion, points are awarded based on accuracy and difficulty, and high-quality contributions are encouraged through the leaderboard. The official website currently provides the following data models for participation:
OpenLedger's longer-term roadmap planning moves from data collection and model building to agent ecology, gradually realizing a complete decentralized AI economic closed loop of "data as assets, models as services, agents as intelligent entities".
- Phase 1 Data Intelligence Layer: The community runs edge nodes to collect and process Internet data and build a high-quality, continuously updated data intelligence infrastructure layer.
- Phase 2 Community Contributions: The community participates in data verification and feedback to jointly create a credible golden dataset and provide high-quality input for model training.
- Phase 3 · Build Models & Claim: Based on golden data, users can train dedicated models and confirm ownership, realizing model assetization and composable value release.
- Phase 4 · Build Agents: Based on the published models, the community can create personalized agents to achieve multi-scenario deployment and continuous collaborative evolution.
OpenLedger's ecological partners cover computing power, infrastructure, tool chains and AI applications. Its partners include decentralized computing power platforms such as Aethir, Ionet, and 0G. AVS on AltLayer, Etherfi, and EigenLayer provides underlying expansion and settlement support; tools such as Ambios, Kernel, Web3Auth, and Intract provide identity authentication and development integration capabilities; in terms of AI models and agents, OpenLedger has joined forces with Giza, Gaib, Exabits, FractionAI, Mira, NetMind and other projects to jointly promote model deployment and agent implementation, and build an open, composable, and sustainable Web3 AI ecosystem.
Over the past year, OpenLedger has hosted the Crypto AI-themed DeAI Summit during Token2049 Singapore, Devcon Thailand, Consensus Hong Kong, and ETH Denver, inviting many core projects and technology leaders in the decentralized AI field to participate. As one of the few infrastructure projects that can continuously plan high-quality industry events, OpenLedger has effectively strengthened its brand recognition and professional reputation in the developer community and Web3 AI entrepreneurial ecosystem through the DeAI Summit, laying a good industry foundation for its subsequent ecological expansion and technology implementation.
5. Financing and Team Background
OpenLedger completed a $11.2 million seed round in July 2024, with investors including Polychain Capital, Borderless Capital, Finality Capital, Hashkey, and several well-known angel investors, such as Sreeram Kannan (EigenLayer), Balaji Srinivasan, Sandeep (Polygon), Kenny (Manta), Scott (Gitcoin), Ajit Tripathi (Chainyoda) and Trevor. The funds will be mainly used to promote the comprehensive implementation of OpenLedger's AI Chain network construction, model incentive mechanism, data infrastructure layer and Agent application ecology.

OpenLedger was founded by Ram Kumar, a core contributor to OpenLedger and a San Francisco-based entrepreneur with a solid technical foundation in AI/ML and blockchain technology. He brings a combination of market insight, technical expertise, and strategic leadership to the project. Ram co-led a blockchain and AI/ML R&D company with annual revenue of over $35 million and played an important role in driving key collaborations, including a strategic joint venture with a Walmart subsidiary. He focuses on ecosystem building and high-leverage collaborations to accelerate the implementation of real-world applications in various industries.
6. Token Economic Model Design and Governance
OPEN is the core functional token of the OpenLedger ecosystem, enabling network governance, transaction operation, incentive distribution and AI Agent operation. It is the economic foundation for building sustainable circulation of AI models and data on the chain. The official token economics is still in the early design stage and the details are not yet fully clarified. However, as the project is about to enter the Token Generation Event (TGE) stage, its community growth, developer activity and application scenario experiments are continuing to accelerate in Asia, Europe and the Middle East:
- Governance and decision-making: OPEN holders can participate in governance voting on model funding, agent management, protocol upgrades, and fund use.
- Transaction fuel and fee payment: As the native gas token of the OpenLedger network, it supports AI-native custom rate mechanisms.
- Incentives and vesting rewards: Developers who contribute high-quality data, models or services can receive OPEN profits based on usage impact.
- Cross-chain bridging capability: OPEN supports L2 ↔ L1 (Ethereum) bridging, improving the multi-chain availability of models and agents.
- AI Agent staking mechanism: AI Agent needs to stake OPEN to run. Poor performance will have its stake reduced to encourage efficient and reliable service output.
Unlike many token governance protocols where influence is tied to the number of coins held, OpenLedger introduces a governance mechanism based on contribution value. Its voting weight is related to the actual value created, rather than simply the capital weight, and it prioritizes contributors who participate in the construction, optimization, and use of models and data sets. This architectural design helps achieve long-term sustainability of governance, prevents speculative behavior from dominating decision-making, and truly fits its vision of a decentralized AI economy that is "transparent, fair, and community-driven."
VII. Data, Model and Incentive Market Structure and Comparison of Competitive Products
As the "Payable AI" model incentive infrastructure, OpenLedger is committed to providing data contributors and model developers with a verifiable, attributable, and sustainable value realization path. It builds a module system with differentiated characteristics around on-chain deployment, call incentives, and intelligent agent combination mechanisms, making it unique in the current Crypto AI track. Although no project has completely overlapped in the overall architecture, OpenLedger and multiple representative projects show high comparability and collaboration potential in key dimensions such as protocol incentives, model economics, and data rights confirmation.
Protocol Incentive Layer: OpenLedger vs. Bittensor
Bittensor is the most representative decentralized AI network at present. It has built a multi-role collaborative system driven by subnets and scoring mechanisms, and incentivizes participants such as models, data and sorting nodes with $TAO tokens. In contrast, OpenLedger focuses on the profit sharing of on-chain deployment and model calls, emphasizing lightweight architecture and agent collaboration mechanism. Although the incentive logic of the two overlaps, the target level and system complexity are obviously different: Bittensor focuses on the general AI capability network base, while OpenLedger is positioned as a value-taking platform for the AI application layer.
Model attribution and call incentives: OpenLedger vs. Sentient
The "OML (Open, Monetizable, Loyal) AI" concept proposed by Sentient is similar to some of OpenLedger's ideas in terms of model confirmation and community ownership, emphasizing the realization of ownership identification and revenue tracking through Model Fingerprinting. The difference is that Sentient focuses more on the training and generation stages of the model, while OpenLedger focuses on the on-chain deployment, calling and profit-sharing mechanism of the model. The two are located at the upstream and downstream of the AI value chain respectively, and are naturally complementary.
Model hosting and trusted inference platform: OpenLedger vs. OpenGradient
OpenGradient focuses on building a secure reasoning execution framework based on TEE and zkML, providing decentralized model hosting and reasoning services, and focusing on the underlying trusted operating environment. In contrast, OpenLedger emphasizes the value capture path after on-chain deployment, and builds a complete closed loop of "training-deployment-calling-profit sharing" around Model Factory, OpenLoRA, PoA and Datanets. The two are in different model life cycles: OpenGradient is biased towards operational credibility, and OpenLedger is biased towards profit incentives and ecological combinations, which have highly complementary space.
Crowdsourcing Models and Valuation Incentives: OpenLedger vs. CrunchDAO
CrunchDAO focuses on the decentralized competition mechanism of financial prediction models, encouraging the community to submit models and receive rewards based on performance, which is suitable for specific vertical scenarios. In contrast, OpenLedger provides a composable model market and a unified deployment framework, with wider versatility and native on-chain monetization capabilities, suitable for the expansion of multi-type intelligent scenarios. The two complement each other in model incentive logic and have synergistic potential.
Community-driven lightweight model platform: OpenLedger vs. Assisterr
Assisterr is built on Solana, encouraging the community to create small language models (SLMs) and increasing usage frequency through code-free tools and $sASRR incentive mechanisms. In comparison, OpenLedger emphasizes the closed-loop traceability and profit-sharing path of data-model-call, and uses PoA to achieve fine-grained incentive allocation. Assisterr is more suitable for low-threshold model collaboration communities, while OpenLedger is committed to building reusable and composable model infrastructure.
Model Factory: OpenLedger vs. Pond
Pond and OpenLedger both provide "Model Factory" modules, but their positioning and service objects are significantly different. Pond focuses on on-chain behavior modeling based on graph neural networks (GNN), mainly for algorithm researchers and data scientists, and promotes model development through competition mechanisms. Pond is more inclined to model competition; OpenLedger is based on language model fine-tuning (such as LLaMA, Mistral), serving developers and non-technical users, emphasizing code-free experience and on-chain automatic profit-sharing mechanism, and building a data-driven AI model incentive ecosystem. OpenLedger is more inclined to data cooperation.
Trusted Reasoning Paths: OpenLedger vs. Bagel
Bagel launched the ZKLoRA framework, which uses the LoRA fine-tuning model and zero-knowledge proof (ZKP) technology to achieve cryptographic verifiability of the off-chain reasoning process and ensure the correctness of the reasoning execution. OpenLedger supports the scalable deployment and dynamic calling of the LoRA fine-tuning model through OpenLoRA, while solving the problem of reasoning verifiability from different angles - it tracks the source of data relied on by reasoning and its influence by attaching a proof of attribution (PoA) to each model output. This not only improves transparency, but also provides rewards for high-quality data contributors and enhances the interpretability and credibility of the reasoning process. In short, Bagel focuses on the verification of the correctness of the calculation results, while OpenLedger achieves responsibility tracking and interpretability of the reasoning process through the attribution mechanism.
Data-side collaboration path: OpenLedger vs. Sapien / FractionAI / Vana / Irys
Sapien and FractionAI provide decentralized data annotation services, while Vana and Irys focus on data sovereignty and confirmation mechanisms. OpenLedger uses the Datanets + PoA module to track the use of high-quality data and distribute incentives on the chain. The former can serve as the upstream of data supply, while OpenLedger serves as the value distribution and call center. The three have good synergy in the data value chain, rather than a competitive relationship.

In summary, OpenLedger occupies the middle layer position of "on-chain model assetization and call incentives" in the current Crypto AI ecosystem. It can not only connect the training network and data platform upward, but also serve the Agent layer and terminal applications downward. It is a key bridge protocol connecting model value supply and on-site calls.
8. Conclusion | From data to model, the path to monetization of AI Chain
OpenLedger is committed to building the "model as an asset" infrastructure in the Web3 world. By building a complete closed loop of on-chain deployment, call incentives, ownership confirmation and intelligent agent combination, it brings AI models into a truly traceable, monetizable and collaborative economic system for the first time. Its technical system built around Model Factory, OpenLoRA, PoA and Datanets provides developers with low-threshold training tools, guarantees the ownership of income for data contributors, and provides application parties with a combinable model call and profit-sharing mechanism, fully activating the "data" and "model" resources that have long been neglected in the AI value chain.
OpenLedger is more like a fusion of HuggingFace + Stripe + Infura in the Web3 world, providing hosting, call billing and on-chain programmable API interfaces for AI models. With the accelerated evolution of data assetization, model autonomy, and Agent modularization, OpenLedger is expected to become an important hub AI chain under the "Payable AI" model.
