
作者:秦景春
審閱:Leon lee
來源:內容公會- 投研
目前,去中心化AI 代理(DAI-Agent)領域備受關注,許多文章介紹了相關項目的特點、解決的問題以及未來潛力。儘管這些文章在一定程度上幫助投資者了解項目,但多數缺乏深度分析,未能深入探討AI 的基本特徵和當前Web3 的現狀。因此,難以明確去中心化AI 在Web3 價值互聯網實踐中的角色,是優化Web3 還是作為關鍵組件。若未釐清去中心化AI 與Web3 價值互聯網經濟之間的內在邏輯,就無法深刻認識去中心化AI 的作用,也難以掌握其核心組件如何解決Web3 存在的問題。例如,去中心化模型和DAI-Agent 這兩個關鍵元件各自解決哪些問題,它們與Web3 之間的內在邏輯是什麼。如果不理解這些內在邏輯,就難以評估該領域的潛在價值。這不僅使我們難以準確選擇高潛力的投資方向,即使選對了賽道和項目,也可能因市場情緒波動而難以堅持。為此,我計劃深入分析當前Web3 的基本現狀和AI 的基本特徵,探討二者融合如何實現價值互聯網的落地,以及Arweave 與AO 如何透過AI 助力這一過程。由於內容豐富,筆者將分兩篇文章詳細闡述:
- 為什麼當前Web3 需要與去中心化AI 的融合才能實現價值互聯網的落地。
目前,許多公鏈項目將主要精力放在底層基礎設施的優化和擴展上,如ETH 及各種L2、Solana 等區塊鏈。但我認為,如果僅追求區塊鏈的擴展,而不將AI 融入其中,很難推進Web3 價值互聯網的落地。目前,Web3 除了擴展能力有限外,還有資料割裂問題,使用者的個人資料分散於不同鍊和DApp,導致管理困難,互動成本高,操作複雜,嚴重限制了使用者積極貢獻資料。此外,去中心化特性導致管理和協同效率低下。這些問題大大限制了Web3 的發展。而AI 具有自主學習、推測與決策的能力,AI Agent 可以作為使用者的智能助手,極大地提升效率。二者融合後,將顯著提升使用者體驗,降低准入門檻,促進Web3 發展。
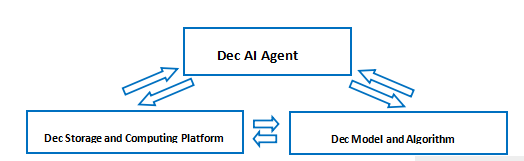
- 去中心化儲存與運算平台、去中心化模型、DAIAgent之間的內在關係:三者結合可以打通Web3資料資產經濟活動閉環,進而實現真正的價值互聯網:
1.1 DAI-Agent
Web3 的核心特徵之一是使用者對自身資料的掌控。 DAIAgent 可協助使用者集中管理並歸集數據,有效解決數據分散在各平台的痛點,同時充當使用者的智慧助手,降低操作難度、提升與Web3 的互動效率。例如,DAIAgent 可輔助使用者管理其DID 生命週期,包括建立、更新和撤銷DID,從而簡化資料管理和使用體驗。這裡有必要詳細探討AI-Agent 與DID 之間的關係,為後續論述打下基礎。在Web3.0 環境中,DID 與DAI-Agent 具有高度互補性和契合性:
a.資料整合與高品質輸入:
AI-Agent 能跨平台整合數據(如社交、醫療、職業數據),有效打破資訊孤島;其智慧演算法可依據DID 的需求對數據進行篩選、清洗和格式化(如評估各數據來源的可信度、去除重複或低價值數據,並按照DID 數據模型規範組織數據),為創建高質量的DID 提供保障。同時,利用差分隱私、同態加密以及最新的多方安全計算(MPC)技術,在不洩露原始資料的前提下完成資料分析計算(例如,在歸集醫療敏感資料時既滿足健康資訊需求,又能保障個人隱私)。此外,隨著跨鏈互通性協定(如Polkadot、Cosmos 等生態體系)的不斷成熟,DAIAgent 有望實現更多資料來源之間的無縫對接,進一步提升資料整合的效率和精確度。去中心化架構不僅避免了單點故障和資料被單一實體掌控的風險,還能透過智慧合約實現自動化資料歸集和即時更新,為建立可信任、動態的數位身分系統提供有力支援。
b.身分認證與授權基礎:
在去中心化環境中,數位身分系統為DAIAgent 提供了必要的身分認證和授權機制,使AI-Agent 能夠在與其他代理商安全互動時證明其合法身分和權限。此過程不僅依賴技術手段,同時也可透過分散式自治組織(DAO)機制,由社區共同參與監管和治理,進一步增強系統的透明性和安全性。
c.增強信任與降低互動成本:
借助DID 系統,DAIAgent 的身份和行為更加透明、可驗證,從而建立信任,促進其他代理的協作;同時,AI-Agent 透過降低用戶與系統的交互成本、簡化複雜操作,有效緩解了因去中心化特性帶來的低效率問題。此外,結合新興的聯邦學習和隱私運算技術,未來DAIAgent 將能夠在不暴露原始資料的情況下,實現跨平台、跨領域的資料協同與智慧決策,為使用者提供更精準、個人化的服務。
1.2去中心化模型
模型在很大程度上可以視為AI-Agent 的“大腦”,是實現智慧的核心組件。未來會湧現大量AI-Agent,並在各行各業發揮作用,而這些專業領域(如醫療、教育、金融等)需要各自對應的AI 模型來支撐。通用AGI 可以滿足使用者的基礎需求,但針對各個專業領域,仍需依賴大量專業化的AI-Agent 來協同工作,這就要求擁有種類繁多的模型。由於去中心化模型相比中心化模型具有無許可、可驗證等優勢,未來必將受到DAI-Agent 的青睞:無許可特性使任何人都能參與模型開發,無須依賴中心化機構的審批,從而推動技術開放;同時,無許可特性使DAIAgent 能更加靈活地調度各類模型,顯著增強智能屬性。除了上述優勢外,未來在資料共享與模型訓練方面,聯邦學習和跨域協作機制也將成為推動去中心化模型發展的關鍵技術,既保護資料隱私又確保模型訓練的效率和安全性。特別是涉及金融、醫療等高敏感性領域時,模型的訓練過程與資料來源均需經過多重驗證,確保系統的整體可信賴性與穩健性。
1.3以區塊鏈技術為核心的去中心化儲存與運算平台
要實現Web3 資料確權,必須建置去中心化儲存和運算平台,以建立可驗證的資料共識基礎設施,為大規模資料交換提供支援。具體來說,Arweave 與AO 的整體解決方案在儲存和運算兩端建構了資料共識基礎設施,從而實現了以下目標:
- 降低資料儲存成本,並保障資料安全與不可竄改性;
- 促進大規模資料交換,為去中心化AI 生態系統的託管和運作提供堅實基礎;
- 透過統一的資料儲存層,簡化資料整合過程,降低因資料分散而導致的整合複雜性;
- 同時,該平台也為建構Web3 中的DID 系統提供了必要的資料支撐,增強了數位身分的管理和應用。
上述三點彼此相輔相成:
- DAIAgent 結合代幣激勵機制促使用戶貢獻數據並積極與Web3 互動,進而形成更多數據;
- 大量資料的產生推動了去中心化儲存和運算平台的發展,因為平台不僅能降低資料儲存成本,還能促進資料確切;
- 去中心化模型需要託管於去中心化平台,既能降低儲存和算力成本,又能確保模型的可驗證性和抗審查性,進而提升模型安全性和信任度,進一步推動模型發展。
此外,去中心化模型訓練需要大量優質數據,而大規模優質數據的出現會顯著提升模型質量;模型質量的提升又會使DAIAgent 越來越智能,進而激發用戶更多交互,產生更多數據;而數據的不斷豐富又進一步推動存儲和計算平台的完善,形成正向循環,環環相扣、生生不息,最終構成完整的數據資產經濟生態系統。這個生態系統打造了資料資產流通的閉環,正是構成真正價值網路生態系統的關鍵。如圖所示:
基於上述邏輯分析,我們可以看到DAI-Agent 只是整個生態中的一個關鍵環節,其發展在很大程度上受制於另外兩部分(即去中心化儲存/運算平台和去中心化模型)的支援。因此,在投資此類專案時,必須注意該專案是否具備建立完整資料資產經濟生態系統的能力,或是否與其他兩方面建立了相對穩定的合作關係。若僅投資單一方向項目,風險將大大增加。另外,目前火熱的ELIZA、VIRTUAL、APC 等DAIAgent 協議雖然支持多元化模型,其中部分協議允許OpenAI 等中心化模型提供商接入,這雖然能滿足用戶多樣化需求,但若中心化模型佔比過高,則會因其缺乏無許可特性而製約協議的長遠發展。
二、這裡我想重點介紹:Arweave 永久儲存+ AO 超平行電腦整體解決方案
1.並行處理能力
與以太坊等網路不同,其基礎層及各個Rollup 通常作為單一進程運行,而AO 支援任意數量進程並行運行,並同時確保計算可驗證性完整。此外,這些網路需在全球同步狀態下運行,而AO 的各個進程則保持獨立狀態。這種獨立性使得每個進程可以處理更多交互,極大地提升了運算擴展性,特別適合高效能和可靠性要求的應用場景。未來,隨著大量DAIAgent 在鏈上不間斷執行任務,對系統擴展性的要求會愈加嚴苛,而AO 的超平行處理能力正好滿足這一需求。
2、具備儲存及運行大模型及其他各類模型的能力
在AO 網路中,目前單一節點記憶體限制為16 GB,而協定層面的記憶體擴充上限可達18 EB,這已足以運行現有AI 領域中的大部分模型(例如Llama3 未量化版本、Falcon 系列以及其他多種模型)。考慮到GPT-4 參數已超過1.76 兆,預計GPT-5 將突破50 兆參數,未來模型規模將持續成長。 AO 的擴展能力非常強,只需物理上增加記憶體或顯示卡,即可對計算單元進行擴展,從而滿足大模型的運行需求。
Arweave 採用獨特的blockweave 技術,使新區塊可與多個舊區塊相連,從而具備極強擴展性,理論上可儲存各類模型及大規模資料。同時,透過WeaveDrive 技術,應用程式可以像存取本機磁碟一樣便捷地存取Arweave 上的數據,這為建立各類應用提供了可能。各類應用程式均可存取Arweave 上的永久儲存數據,而AO+Arweave 已從計算與儲存兩方面建構了數據確權的基礎設施,為大規模數據資產交換奠定了基礎,這對有意在AO 平台上開發應用的開發者極具吸引力。同時,各應用場景為各類模型和DAI-Agent 提供了多元化的落地場景,從而促進了AI 生態的發展。
3.數據是AI 生態系統三大要素之一——AO + Arweave 生態中大部分數據為高品質數據,並具備統一數據儲存層
大規模且高品質的資料對模型訓練至關重要。高品質資料通常具備準確性、一致性、有效性、完整性、及時性和唯一性等特徵。在AO+Arweave 生態系中,流通的數據大多符合這些特性。詳細技術實作細節請閱讀我的上一篇文章《Arweave 永久儲存+ AO 超平行電腦:建構資料共識基礎架構》。這裡需要特別強調Arweave 永久儲存的優勢:正因其永久儲存屬性,儲存的資料往往更為關鍵;資料儲存時間越長,其價值越能體現,因為這不僅便於保存與追溯,也利於資料確權。大規模高品質資料對於AI 訓練極為重要,而Arweave 作為統一資料儲存層,具備整合各項目資料的能力,相較之下,以太坊、Solana 等由於缺乏統一儲存層,資料整合難度更高。 Arweave 的這些特性對資料收集、整合和完整性保障起到了關鍵作用,而這對於建構Web3 內的DID 至關重要:統一資料儲存層遠比跨平台資料整合更便捷。此外,AO 與Arweave 的整合確保所有代理交互資料均可永久存儲,這對建立問責機制及DID 和聲譽系統提供了有力支撐。例如,目前RedStone 專案正藉助Arweave 建構DID,並建立問責機制,為AI-Agent 的發展提供基礎設施支援。
4、AO + Arweave 賦予AI 較高的可驗證性
可驗證性對AI 的發展至關重要,它確保AI 模型的預測和輸出具備透明、防篡改且可獨立驗證的特性,為AI 提供更高的可信度和安全性,從而使其能在金融、醫療、法律、自動駕駛等高信任度領域得到廣泛應用。同時,可驗證性也使開發者更放心地共享和協作模型,無需擔憂被惡意竄改。 AO+Arweave 採用SCP 存儲方式,讓AO 內的所有數據和模型均可在Arweave 上全息存儲,任何人均可驗證數據源、模型運行過程及輸出結果;同時,計算單元提供的加密簽名進一步確保計算結果的真實性與完整性。隨著零知識證明技術和分散式驗證機制的不斷完善,未來不僅可以對模型輸出進行即時驗證,還可以對模型的訓練資料、參數更新等全過程進行溯源和審計,從而形成一個全方位、多層次的信任體系。此外,AO 與PADO 共同發起的可驗證機密計算(vcc)利用ZKFHE(零知識全同態加密)技術,既能保障資料和模型的隱私性,也確保其可驗證性和可計算性。這樣的機制不僅大大降低了資料共享的風險,同時也為模型提供者提供了智慧財產權保護,鼓勵更多優質模型的開放和共享。結合代幣激勵機制,此信任體係有望進一步激發用戶積極貢獻數據,推動整個AI 生態系統朝向更高水準發展。
AO+Arweave 生態系基礎組件及相互關係如圖所示:
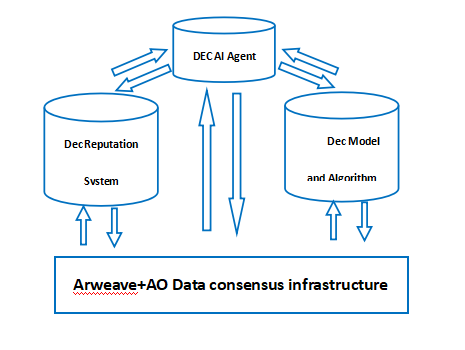
綜上所述,AO+Arweave 生態系統為去中心化AI 提供了優越的運作環境:它不僅具備出色的擴展性和託管能力,適合支撐去中心化AI 生態系統,同時在大規模高品質資料儲存與交換、並行運算以及可驗證性等方面擁有顯著優勢。這些因素共同促使AO+Arweave 生態系統成為去中心化AI 發展的理想平台,而透過上述論證,Web3 價值互聯網生態系統落地所需的三大要素中,去中心化AI 無疑扮演著至關重要的角色。由此可見,AO+Arweave+AI 可望大幅推動Web3 落地!









