
著者: 秦 静春
レビュアー: レオン・リー
出典: コンテンツ協会 - 投資調査
元々はPermaDAOに掲載されました
オリジナルリンク: https://permadao.com/permadao/AO-Arweave-AI-1ad27607c43980178fe9f03f495d54d4
近年、AI技術の急速な発展と大規模モデルトレーニングの需要の高まりにより、分散型AIインフラストラクチャは業界で徐々に議論される話題になってきました。従来の集中型コンピューティング プラットフォームはコンピューティング能力を継続的にアップグレードしていますが、データの独占と高いストレージ コストにより、限界がますます明らかになりつつあります。逆に、分散型プラットフォームは、ストレージコストを削減できるだけでなく、分散型検証メカニズムを通じてデータと計算の不変性を確保できるため、AIモデルのトレーニング、推論、検証などの重要なリンクで重要な役割を果たします。さらに、Web3は現在、データの断片化、非効率的なDAO組織、プラットフォーム間の相互運用性の低さなどの問題を抱えています。そのため、さらなる発展のためには、分散型AIと統合する必要があります。
この記事では、メモリ制限、データストレージ、並列コンピューティング機能、検証可能性という 4 つの側面から、さまざまな主流プラットフォームの長所と短所を比較・分析し、分散型 AI の分野で AO+Arweave システムが明らかな競争上の優位性を発揮する理由を詳しく説明します。
1. さまざまなプラットフォームの比較分析: AO+Arweave がユニークな理由
1.1 メモリと計算能力の要件
AI モデルの規模が拡大し続けるにつれて、メモリと計算能力がプラットフォームの能力を測定するための重要な指標になります。比較的小さなモデル (Llama-3-8 B など) を実行する場合を例にとると、少なくとも 12 GB のメモリが必要です。また、1 兆を超えるパラメータを持つ GPT-4 などのモデルでは、メモリとコンピューティング リソースに対する要件が驚くほど大きくなります。トレーニング プロセスでは、行列計算、バックプロパゲーション、パラメーター同期などの多数の操作で並列コンピューティング機能をフルに活用する必要があります。
AO+Arweave : AO は並列コンピューティング ユニット (CU) とアクター モデルを通じて、タスクを複数のサブタスクに分割して同時に実行し、きめ細かい並列スケジューリングを実現します。このアーキテクチャは、トレーニング中に GPU などのハードウェアの並列処理の利点を最大限に活用するだけでなく、タスクのスケジュール設定、パラメータの同期、勾配の更新などの主要なリンクの効率を大幅に向上させます。
ICP : ICP サブネットはある程度の並列コンピューティングをサポートしていますが、統合コンテナ内で実行する場合にのみ粗粒度の並列処理を実現できるため、大規模モデルトレーニングにおけるきめ細かいタスクスケジューリングのニーズを満たすことが難しく、全体的な効率が不十分になります。
Ethereum と Base Chain : どちらもシングルスレッド実行モードを使用します。これらのアーキテクチャ設計は、もともと分散型アプリケーションとスマート コントラクトを対象としていました。複雑な AI モデルのトレーニング、実行、検証に必要な高度な並列コンピューティング機能を備えていません。
コンピューティングパワーの需要と市場競争
Deepseek などのプロジェクトの人気が高まるにつれて、大規模モデルのトレーニングのハードルは下がり続け、ますます多くの中小企業が競争に加わり、市場におけるコンピューティング リソースの不足が深刻化する可能性があります。このような状況では、分散並列コンピューティング機能を備えた AO のような分散コンピューティング インフラストラクチャがますます普及するでしょう。 AO+Arweaveは分散型AIのインフラストラクチャとして、Web3価値インターネットの実装の重要なサポートになります。
1.2 データストレージと経済性
データストレージも重要な指標の 1 つです。 Ethereum などの従来のブロックチェーン プラットフォームは、オンチェーン ストレージのコストが非常に高いため、通常は主要なメタデータの保存にのみ使用され、大規模なデータ ストレージは IPFS や Filecoin などのオフチェーン ソリューションに転送されます。
- Ethereum プラットフォーム: ほとんどのデータを保存するのに外部ストレージ (IPFS、Filecoin など) に依存しています。データの不変性は保証できますが、オンチェーン書き込みコストが高いため、大量のデータをチェーンに直接保存することはできません。
- AO+Arweave : Arweave の永続的かつ低コストのストレージ機能を活用して、データの長期アーカイブと変更不能性を実現します。 AI モデルのトレーニング データ、モデル パラメーター、トレーニング ログなどの大規模データの場合、Arweave はデータ セキュリティを確保するだけでなく、その後のモデル ライフサイクル管理を強力にサポートします。同時に、AO は Arweave に保存されているデータを直接呼び出して、完全なデータ資産経済閉ループを構築し、Web3 における AI 技術の実装と応用を促進します。
- その他のプラットフォーム (Solana、ICP) : Solana はアカウント モデルを通じて状態ストレージを最適化していますが、大規模なデータ ストレージは依然としてオフチェーン ソリューションに依存する必要があります。ICP は組み込みのコンテナー ストレージを使用し、動的な拡張をサポートしていますが、長期のデータ ストレージには Cycles の継続的な支払いが必要であり、全体的な経済性はより複雑です。
1.3 並列計算機能の重要性
大規模な AI モデルをトレーニングする場合、計算集約型のタスクの並列処理が効率向上の鍵となります。多数の行列演算を複数の並列タスクに分割すると、GPU などのハードウェア リソースを最大限に活用しながら、時間コストを大幅に削減できます。
- AO : AO は、独立したコンピューティング タスクとメッセージ パッシング調整メカニズムを通じて、きめ細かな並列コンピューティングを実現します。そのアクター モデルは、単一のタスクを数百万のサブプロセスに分割し、複数のノード間で効率的に通信することをサポートします。このアーキテクチャは、大規模モデルのトレーニングや分散コンピューティングのシナリオに特に適しています。理論上は、非常に高い TPS (1 秒あたりのトランザクション数) を実現できます。実際には I/O などの制限がありますが、従来のシングル スレッド プラットフォームをはるかに上回っています。 。
- Ethereum と Base Chain : シングルスレッドの EVM 実行モードのため、どちらも複雑な並列コンピューティング要件に対応できず、大規模な AI モデルのトレーニングの要件を満たすことができません。
- Solana と ICP : Solana の Sealevel ランタイムはマルチスレッド並列処理をサポートしていますが、並列粒度は比較的粗く、ICP は依然として主に単一のコンテナー内でシングルスレッドであるため、非常に並列化されたタスクを処理するときに明らかなボトルネックが発生します。
1.4 検証可能性とシステムの信頼性
分散型プラットフォームの主な利点は、グローバルなコンセンサスと改ざん防止ストレージメカニズムを通じて、データとコンピューティング結果の信頼性を大幅に向上できることです。
- イーサリアム:グローバルなコンセンサス検証とゼロ知識証明(ZKP)エコロジーを通じて、スマートコントラクトの実行とデータストレージの透明性と検証性が非常に高くなることを保証しますが、それに伴う検証コストは比較的高くなります。
- AO+Arweave : AO は、すべてのコンピューティング プロセスを Arweave にホログラフィックに保存し、「決定論的仮想マシン」を使用して結果の再現を保証することで、完全な監査チェーンを構築します。このアーキテクチャは、コンピューティング結果の検証可能性を向上させるだけでなく、システム全体の信頼性を高め、AI モデルのトレーニングと推論を強力にサポートします。
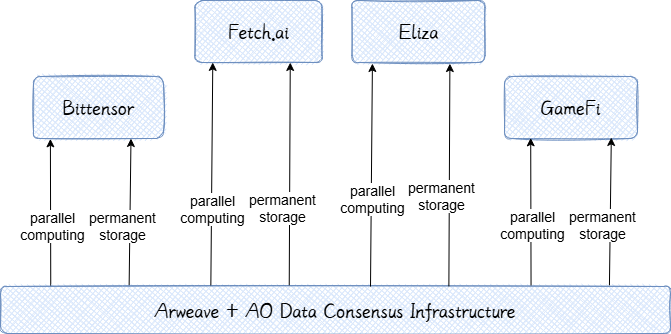
2. AO+Arweaveと垂直分散型AIプロジェクトの補完関係
分散型 AI の分野では、Bittensor、 Fetch.ai 、Eliza、GameFi などの垂直プロジェクトが、それぞれのアプリケーション シナリオを積極的に模索しています。インフラストラクチャ プラットフォームとしての AO+Arweave の利点は、効率的な分散コンピューティング能力、永続的なデータ ストレージ、フルチェーン監査機能を提供することで、これらの垂直プロジェクトに必要な基本サポートを提供できることです。
2.1 技術補完の例
ビッテンソル:
Bittensor の参加者は AI モデルをトレーニングするために計算能力を提供する必要があり、並列計算リソースとデータ ストレージに対する要求が非常に高くなります。 AO の超並列コンピューティング アーキテクチャにより、多数のノードが同じネットワーク内で同時にトレーニング タスクを実行し、オープン メッセージ パッシング メカニズムを通じてモデル パラメーターと中間結果を迅速に交換できるため、従来のブロックチェーンの順次実行によって発生するボトルネックを回避できます。このロックフリーの並行アーキテクチャは、モデルの更新速度を向上させるだけでなく、全体的なトレーニング スループットも大幅に向上させます。同時に、Arweave が提供する永続的なストレージは、主要なデータ、モデルの重み、パフォーマンス評価結果を保存するのに最適なソリューションを提供します。トレーニング プロセス中に生成された大規模なデータ セットは、リアルタイムで Arweave に書き込むことができます。データの不変性により、新しく追加されたノードは最新のトレーニング データとモデルのスナップショットを取得できるため、ネットワーク参加者は統一されたデータ基盤に基づいてトレーニングを共同で行うことができます。この組み合わせにより、データ配布プロセスが簡素化されるだけでなく、モデルのバージョン管理と結果検証のための透明で信頼性の高い基盤が提供され、Bittensor ネットワークは分散化の利点を維持しながら集中型クラスターに近い計算効率を実現できるため、分散型機械学習のパフォーマンス上限が大幅に向上します。
Fetch.aiの自律経済エージェント (AEA):
マルチエージェント協働システムFetch.aiにおいても、AO+Arweaveの組み合わせにより優れた相乗効果を発揮します。 Fetch.ai は、自律エージェント (エージェント) がチェーン上で経済活動に協力できるようにする分散型プラットフォームを構築しました。このようなアプリケーションでは、多数のエージェントの同時操作とデータ交換を同時に処理する必要があり、コンピューティングと通信に非常に高い負荷がかかります。 AO はFetch.aiに高性能な動作環境を提供します。各自律エージェントは、AO ネットワーク内の独立したコンピューティング ユニットとみなすことができます。複数のエージェントは、互いにブロックすることなく、異なるノード上で複雑な計算と決定ロジックを並行して実行できます。オープン メッセージング メカニズムにより、エージェント間の通信がさらに最適化されます。エージェントは、オンチェーン メッセージ キューを介して非同期的に情報を交換し、アクションをトリガーできるため、従来のブロックチェーンでのグローバル状態の更新によって発生する遅延の問題を回避できます。 AO のサポートにより、数百のFetch.aiエージェントがリアルタイムで相互に通信、競争、協力し、現実世界に近い経済活動のリズムをシミュレートできます。同時に、Arweave の永続的なストレージ機能により、 Fetch.aiのデータ共有と知識保持が可能になります。各エージェントが操作中に生成または収集した重要なデータ (市場情報、インタラクション ログ、プロトコル契約など) は、Arweave に送信して保存することができ、中央サーバーの信頼性を信頼することなく、他のエージェントまたはユーザーがいつでも取得できる永続的なパブリック メモリ ライブラリを形成します。これにより、エージェント間のコラボレーションの記録がオープンかつ透明になります。たとえば、エージェントによって発行されたサービス条件やトランザクションの見積もりが Arweave に書き込まれると、それらはすべての参加者によって認識される公開記録となり、ノード障害や悪意のある改ざんによって失われることはありません。 AO の高同時実行コンピューティングと Arweave の信頼できるストレージの助けにより、 Fetch.aiマルチエージェント システムはチェーン上で前例のないほど深いコラボレーションを実現できます。
Eliza マルチエージェントシステム:
従来の AI チャットボットは通常、クラウドに依存し、強力なコンピューティング能力を使用して自然言語を処理し、データベースを使用して長期的な会話やユーザーの好みを保存します。 AO の超並列コンピューティングの助けを借りて、オンチェーン インテリジェント アシスタントはタスク モジュール (言語理解、対話生成、感情分析など) を複数のノードに分散して並列処理し、多数のユーザーが同時に質問した場合でも迅速に応答できます。 AO のメッセージ パッシング メカニズムにより、モジュール間の効率的なコラボレーションが保証されます。たとえば、言語理解モジュールがセマンティクスを抽出した後、非同期メッセージを通じて結果を応答生成モジュールに送信するため、分散アーキテクチャでの対話プロセスはスムーズに維持されます。同時に、Arweave は Eliza の「長期記憶バンク」として機能します。ユーザーのインタラクション記録、好み、アシスタントが学習した新しい知識はすべて暗号化され、永久に保存されます。間隔がどれだけ長くても、ユーザーは再度インタラクションするときに以前のコンテキストを取得して、パーソナライズされた一貫した応答を実現できます。永続的なストレージは、集中型サービスでのデータ損失やアカウント移行によるメモリ損失を回避するだけでなく、AI モデルの継続的な学習のための履歴データのサポートも提供し、オンチェーン AI アシスタントを「使うほどに賢くなる」ものにします。
GameFi ライブプロキシアプリ:
分散型ゲーム (GameFi) では、AO と Arweave の相補的な特性が重要な役割を果たします。従来の MMO は、大量の同時コンピューティングと状態ストレージを集中型サーバーに依存していますが、これはブロックチェーンの分散型の概念に反しています。 AO は、ゲームロジックと物理シミュレーションタスクを分散ネットワークに分散して並列処理することを提案しています。たとえば、オンチェーンの仮想世界では、さまざまなエリアのシーンシミュレーション、NPC の動作決定、プレイヤーのインタラクションイベントを各ノードで同時に計算し、メッセージパッシングを通じてリージョン間の情報を交換して、完全な仮想世界を共同で構築することができます。このアーキテクチャにより、単一サーバーのボトルネックが解消され、プレイヤー数の増加に応じてゲームがコンピューティング リソースを線形に拡張し、スムーズなエクスペリエンスを維持できるようになります。同時に、Arweave の永続的なストレージは、ゲームの信頼性の高いステータス記録と資産管理を提供します。主要な状態 (マップの変更、プレーヤー データなど) と重要なイベント (レア アイテムの取得、プロットの進行など) は、オンチェーンの証拠として定期的に固められます。プレーヤー資産のメタデータとメディア コンテンツ (キャラクター スキン、アイテム NFT など) も直接保存され、永続的な所有権と改ざん防止が確保されます。システムがアップグレードされたり、ノードが交換されたりしても、Arweave によって保存された履歴状態は復元できるため、技術の変化によってプレイヤーの成果や財産が失われることはありません。このデータが突然消えることを望むプレイヤーはいません。これまでにも同様の事件が何度も発生しています。たとえば、何年も前、ブリザードが World of Warcraft の魔術師のライフストロー スキルを突然キャンセルしたとき、Vitalik Buterin は激怒しました。さらに、永続的なストレージにより、プレイヤー コミュニティがゲームの記録に貢献できるようになり、重要なイベントをチェーン上に永続的に保存できます。 AO の高強度並列コンピューティングと Arweave の永続ストレージの助けにより、この分散型ゲーム アーキテクチャは、パフォーマンスとデータの永続性における従来のモデルのボトルネックを効果的に打破します。
2.2 エコシステムの統合と相補的な利点
AO+Arweave は、垂直 AI プロジェクト向けのインフラストラクチャ サポートを提供するだけでなく、オープンで多様性があり、相互接続された分散型 AI エコシステムの構築にも取り組んでいます。 AO+Arweave は、単一分野に焦点を当てたプロジェクトと比較して、より広いエコシステムの範囲とより多くのアプリケーション シナリオを備えています。その目標は、データ、アルゴリズム、モデル、コンピューティング パワーをカバーする完全なバリュー チェーンを構築することです。このような巨大なエコシステムでのみ、Web3 データ資産の潜在能力が真に発揮され、健全で持続可能な分散型 AI 経済のクローズドループが形成されるのです。
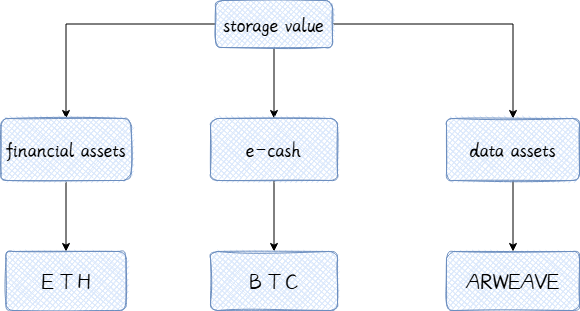
3. Web3 価値インターネットと永久価値ストレージ
Web3.0 時代の到来により、データ資産がインターネット上で最も重要なリソースになります。ビットコイン ネットワークの「デジタル ゴールド」の保管と同様に、Arweave が提供する永久ストレージ サービスでは、貴重なデータ資産を長期間保存し、改ざんできないようにすることができます。現在、インターネット大手によるユーザーデータの独占により、個人データの価値を反映することが困難になっています。Web3時代では、ユーザーが自分のデータを所有し、トークンインセンティブメカニズムを通じてデータ交換が効果的に実現されます。
価値の保存の特性:
Arweave は、Blockweave、SPoRA、およびバンドル技術を通じて強力な水平スケーラビリティを実現し、大規模なデータ ストレージ シナリオで特に優れたパフォーマンスを発揮します。この機能により、Arweave は永続的なデータ ストレージのタスクを実行するだけでなく、その後の知的財産管理、データ資産トランザクション、AI モデルのライフサイクル管理を強力にサポートできるようになります。
データ資産経済:
データ資産は、Web3 の価値あるインターネットの中核です。将来的には、個人データ、モデルパラメータ、トレーニングログなどが貴重な資産となり、トークンインセンティブやデータ権利確認などの仕組みを通じて効率的な循環が実現されるでしょう。 AO+Arweaveはこのコンセプトに基づいて構築されたインフラストラクチャであり、データ資産の循環チャネルを開き、Web3エコシステムに継続的な活力を注入することを目的としています。
IV. リスク、課題、将来の見通し
AO+Arweave には多くの技術的な利点がありますが、実際には次のような課題に直面しています。
経済モデルの複雑さ
低コストのデータ保存と効率的なデータ転送を確保するには、AO の経済モデルを AR トークン経済システムと深く統合する必要があります。このプロセスには、複数のノード(MU、SU、CU など)間のインセンティブと罰則のメカニズムが含まれ、セキュリティ、コスト、スケーラビリティのバランスをとるために、柔軟な SIV サブステーキングのコンセンサス メカニズムを使用する必要があります。実際の実装プロセスでは、ノード数とタスク要件のバランスを取り、アイドルリソースや不十分な利益を回避する方法が、プロジェクト関係者が真剣に検討する必要がある問題です。
分散型モデルとアルゴリズム市場の構築が不十分
現在の AO+Arweave エコシステムは、主にデータストレージとコンピューティングパワーのサポートに重点を置いており、完全な分散型モデルとアルゴリズムの市場はまだ形成されていません。安定したモデルプロバイダーがなければ、エコシステムにおける AI エージェントの開発は制限されます。したがって、高い競争障壁と長期的な堀を形成するために、エコロジカルファンドを通じて分散型モデル市場プロジェクトを支援することが推奨されます。
多くの課題に直面しながらも、Web 3.0 時代の到来とともに、データ資産の確認と流通が進み、インターネット全体の価値体系の再構築が促進されるでしょう。 AO+Arweaveはインフラの先駆者として、この変革において重要な役割を果たし、分散型AIエコシステムとWeb3価値インターネットの構築に貢献することが期待されています。
結論は
メモリ、データ ストレージ、並列コンピューティング、検証可能性という 4 つの側面の詳細な比較分析に基づいて、AO+Arweave は、特に大規模な AI モデルのトレーニングのニーズを満たし、ストレージ コストを削減し、システムの信頼性を向上させるという点で、分散型 AI タスクのサポートにおいて明らかな利点があると考えています。同時に、AO+Arweaveは垂直分散型AIプロジェクトに強力なインフラストラクチャサポートを提供するだけでなく、完全なAIエコシステムを構築する可能性も備えており、Web3データ資産経済活動の閉ループの形成を促進し、より大きな変化をもたらします。詳細については、 https://mp.weixin.qq.com/s/h42BPZxGoZE1_C_UeDMOOQ を参照してください。
今後、経済モデルの継続的な改善、エコシステムの規模の段階的な拡大、分野間の協力の深化に伴い、AO+Arweave+AIはWeb3価値インターネットの重要な柱となり、データ資産の権利確認、価値交換、分散型アプリケーションに新たな変化をもたらすことが期待されます。実際の実装プロセスにはまだ一定のリスクと課題がありますが、継続的な試行錯誤と最適化を通じて、テクノロジーとエコロジーは最終的に画期的な進歩をもたらすでしょう。
上記内容はあくまでも個人の意見です。どなたでもお気軽にご意見・ご感想をお聞かせください。










