
Original: YQ
Compiled by Yuliya, PANews
On October 20th, Amazon Web Services (AWS) experienced another major outage, severely impacting cryptocurrency infrastructure. Beginning at approximately 4:00 PM Beijing time, issues with AWS in the US-EAST-1 region (Northern Virginia data center) caused downtime for Coinbase and dozens of other major crypto platforms, including Robinhood, Infura, Base, and Solana.
AWS has acknowledged an "increased error rate" in its core database and compute services—Amazon DynamoDB and EC2—which thousands of companies rely on. This real-time outage provides direct and stark evidence of the core argument of this article: crypto infrastructure's reliance on centralized cloud service providers creates systemic vulnerabilities that are repeatedly exposed under pressure.
The timing is alarming. Just ten days after a $19.3 billion cascade of liquidations exposed infrastructure failures at the exchange level, the AWS outage demonstrated that the problem had spread beyond individual platforms to the underlying cloud infrastructure. When AWS fails, the ripple effect impacts centralized exchanges, decentralized platforms that still rely on centralized components, and the countless services that rely on them.
This isn't an isolated incident, but rather the continuation of a long-standing pattern. Similar AWS outages occurred in April 2025, December 2021, and March 2017, each disrupting major crypto services. The question is no longer "if" it will happen again, but "when" and "what will trigger it."
Liquidation Falls on October 10-11, 2025
The liquidation chain event, which occurred on October 10-11, 2025, is a prime example of the mechanisms of infrastructure failure. At 8:00 PM UTC on October 10 (4:00 AM Beijing Time on October 11), a major geopolitical announcement triggered a widespread market sell-off. Within a single hour, liquidations reached $6 billion. By the time Asian markets opened, the total loss of leveraged positions had reached $19.3 billion, affecting 1.6 million trader accounts.
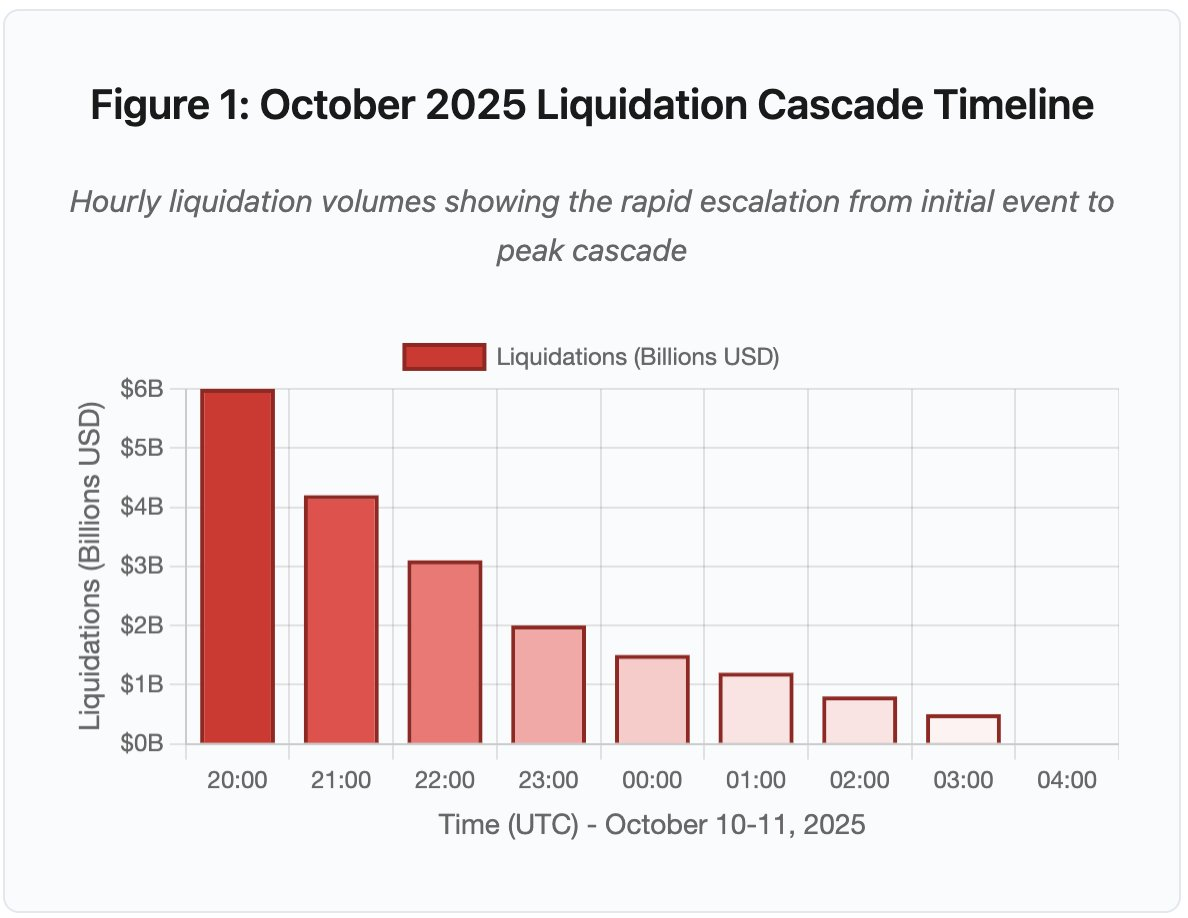
Figure 1: Liquidation Waterfall Timeline, October 2025 (UTC)
Key turning points include API speed limits, market maker exits, and a sharp drop in order book liquidity.
- 20:00-21:00: Initial impact – liquidation of $6 billion (red zone)
- 21:00-22:00: Liquidation peak - $4.2 billion, API begins to throttle
- 22:00-04:00: Continued deterioration - $9.1 billion, extremely thin market depth
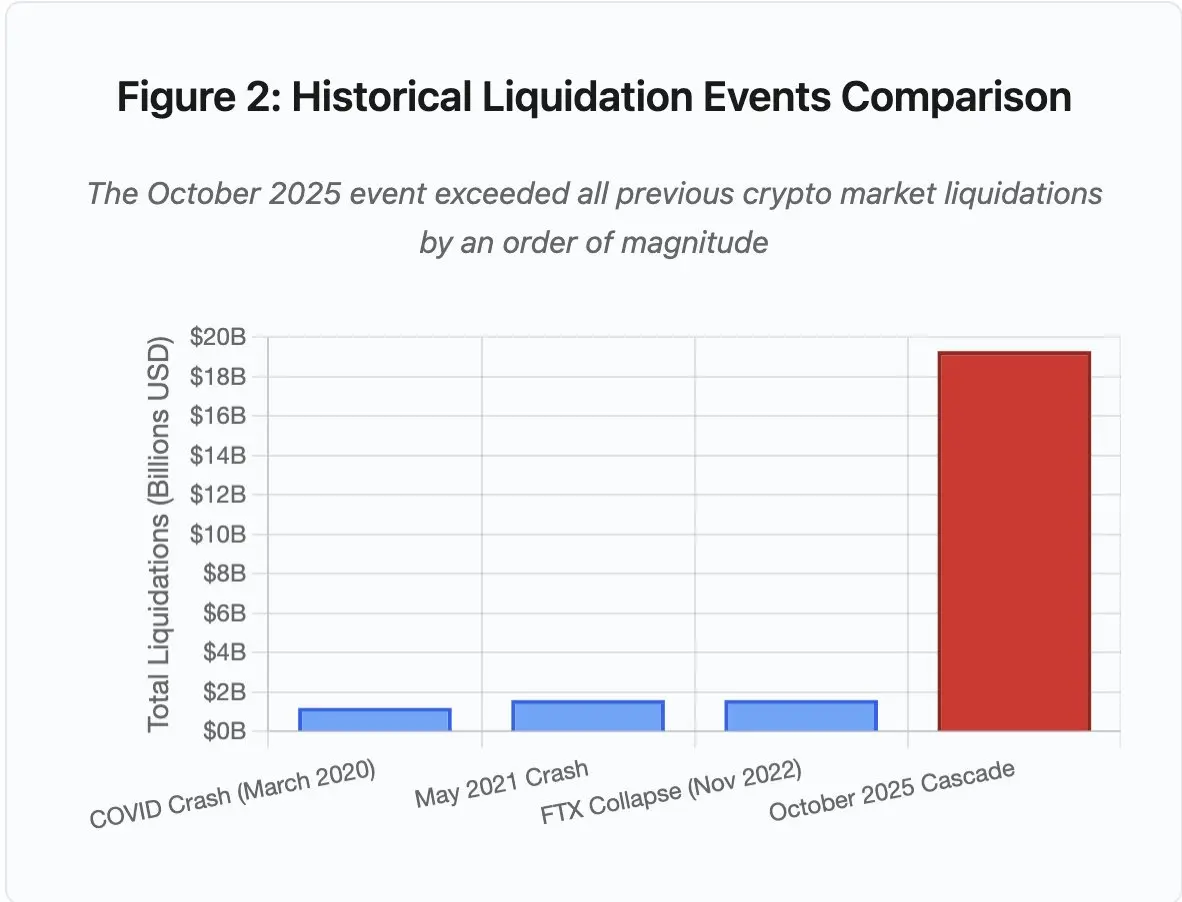
Figure 2: Comparison of historical liquidation events
The scale of this event exceeds any previous crypto market event by at least an order of magnitude. A vertical comparison reveals the leap-forward nature of this event:
- March 2020 (during the pandemic): $1.2 billion
- May 2021 (market crash): $1.6 billion
- November 2022 (FTX crash): $1.6 billion
- October 2025: $19.3 billion, 16 times the previous record
However, liquidation data is only superficial. The more critical question lies at the mechanistic level: how can external market events trigger such a specific failure mode? The answer reveals systemic weaknesses in the architecture of centralized exchanges and the design of blockchain protocols.
Off-chain failure: Architectural issues with centralized exchanges
Infrastructure overload and rate limiting
Exchange APIs typically implement rate limits to prevent abuse and maintain a stable server load. Under normal circumstances, these limits prevent attacks and ensure smooth trading. However, during periods of extreme volatility, when thousands of traders attempt to adjust their positions simultaneously, these limits can become a bottleneck.
During this period, centralized exchanges (CEXs) limited liquidation notifications to one per second, despite the system's need to process thousands. This resulted in a significant drop in transparency, preventing users from understanding the extent of the cascading liquidations in real time. Third-party monitoring tools indicated hundreds of liquidations per minute, while official data showed far fewer.
API speed limits prevented traders from adjusting their positions during the crucial first hour. Connection request timeouts, order placement failures, unexecuted stop-loss orders, and delayed position data updates all transformed market events into operational crises.
Traditional exchanges typically allocate resources for "normal load + safety margins," but the gap between normal load and extreme load is significant. Average daily trading volume is insufficient to anticipate peak demand under extreme pressure. During a cascading liquidation period, trading volume can surge 100-fold, and position inquiries can soar 1,000-fold. With every user checking their account simultaneously, the system can be nearly paralyzed.
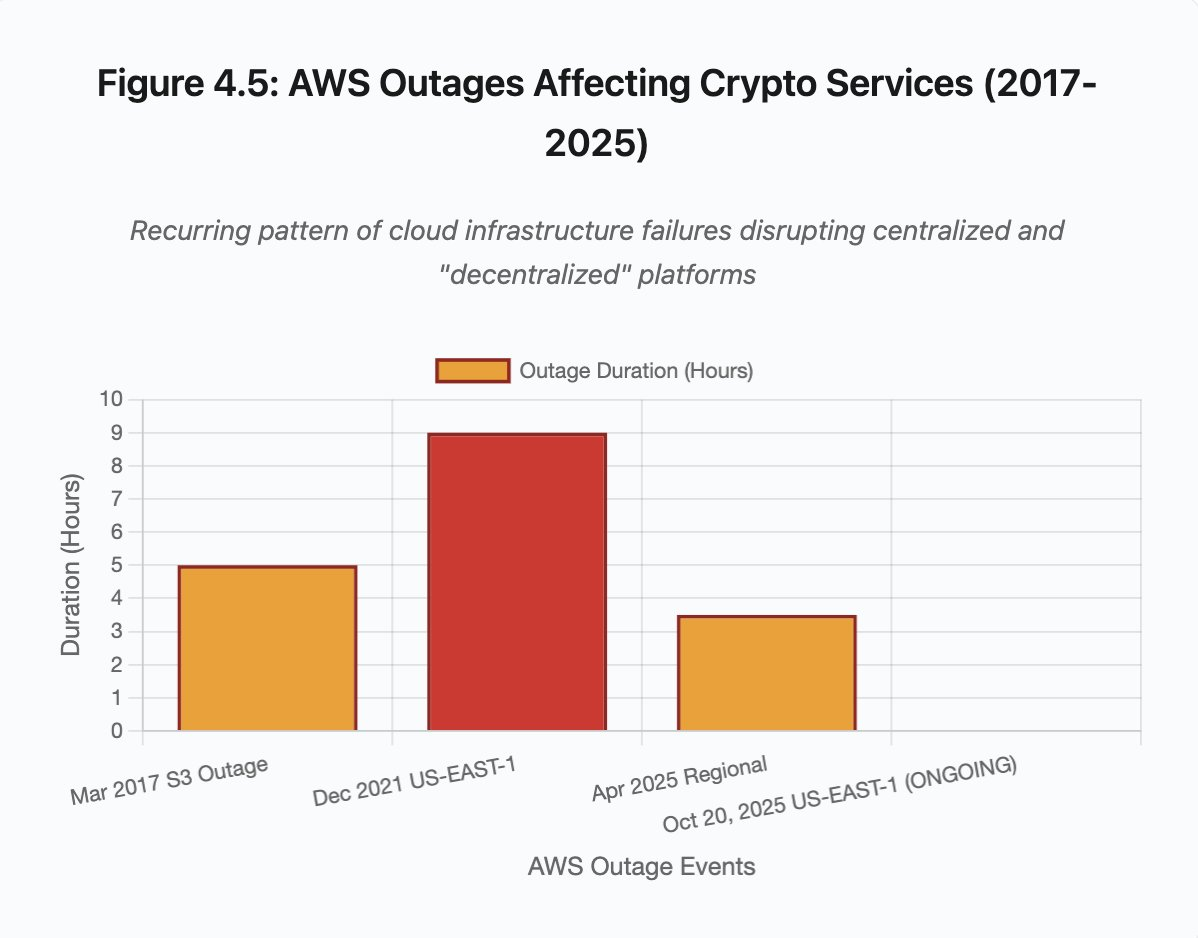
Figure 4.5: AWS outage affecting encryption services
While automatic scaling of cloud infrastructure can be helpful, it's not instantaneous. Creating additional database replicas takes minutes, as does spawning a new API gateway instance. During this time, the margin system continues to mark positions for settlement based on price data distorted by order book congestion.
Oracle Manipulation and Pricing Vulnerabilities
The October liquidation incident exposed a critical design flaw in the margin system: some exchanges calculated collateral values based on internal spot prices rather than external oracle prices. Under normal market conditions, arbitrageurs were able to maintain price consistency across exchanges, but this linkage mechanism failed when the infrastructure came under pressure.
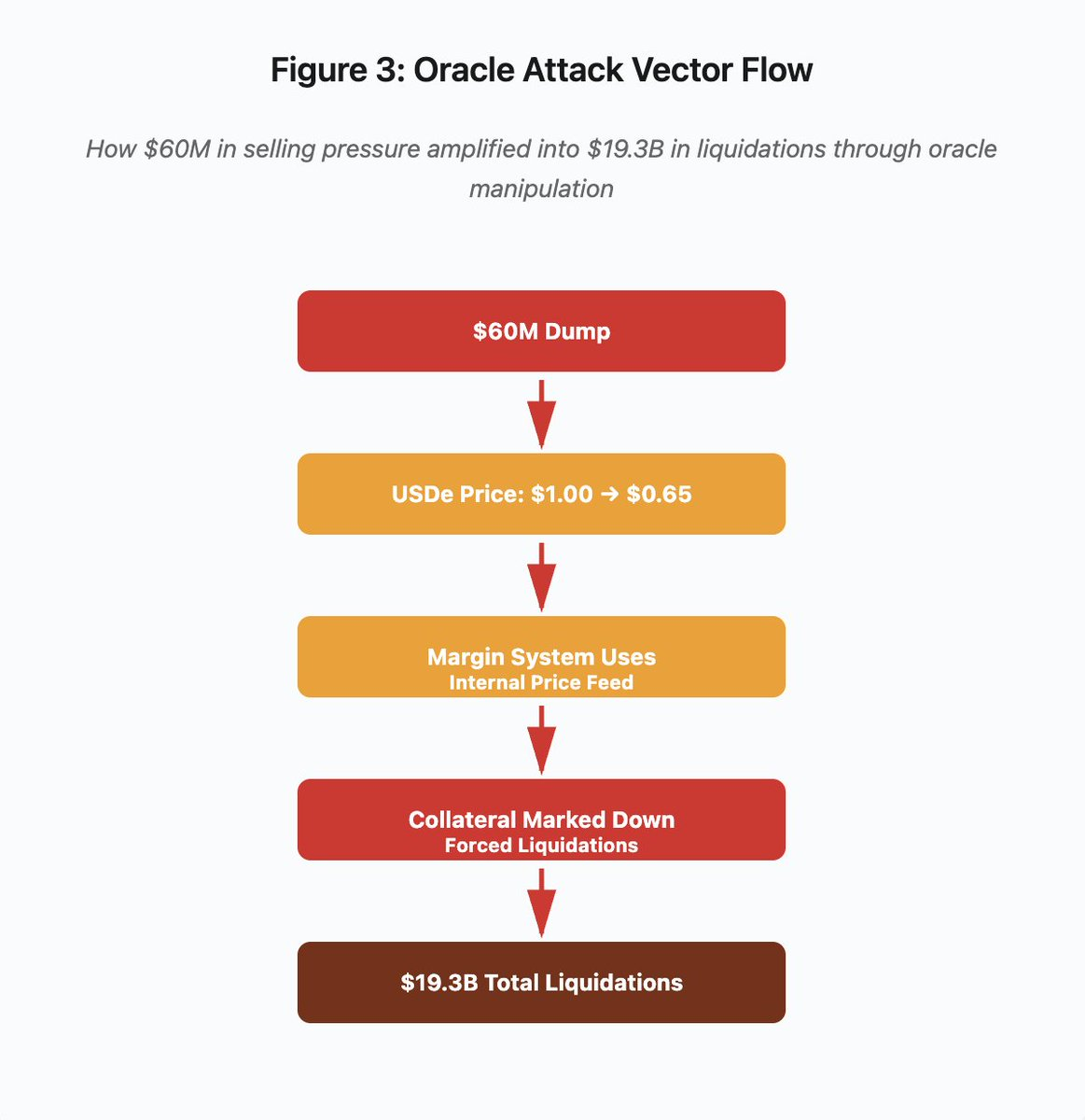
Figure 3: Oracle manipulation flow chart
The attack path can be divided into five stages:
- Initial sell-off: $60 million of selling pressure on USDe
- Price Manipulation: USDe Plummets from $1.00 to $0.65 on a Single Exchange
- Oracle failure : Margin system uses manipulated internal prices
- Trigger chain : Collateral is undervalued, triggering forced liquidation
- Amplification Effect: $19.3 billion in liquidations (322x amplification)
The attack exploited Binance's use of spot market prices to price wrapped synthetic collateral. When an attacker dumped $60 million worth of USDe into a relatively thin order book, the spot price plummeted from $1.00 to $0.65. The margin system, configured to mark collateral to the spot price, reduced the value of all USDe-collateralized positions by 35%. This triggered margin calls and forced liquidations for thousands of accounts.
These liquidations forced more sell orders into the same illiquid market, further depressing prices. The margin system observed these lower prices and wrote down even more positions. This feedback loop amplified the $60 million in selling pressure by 322 times, ultimately leading to $19.3 billion in forced liquidations.

Figure 4: Liquidation Waterfall Feedback Loop
This feedback loop diagram illustrates the self-reinforcing nature of waterfall:
Price falls → triggers liquidation → forced sell → price falls further → [cycle repeats]
With a properly designed oracle system, this mechanism wouldn't work. If Binance had used a time-weighted average price (TWAP) across multiple exchanges, instantaneous price manipulation wouldn't have affected collateral valuation. If they had used aggregated price feeds from Chainlink or other multi-source oracles, the attack would have failed.
A similar issue was exposed a few days ago with the wBETH incident. Wrapped Binance ETH (wBETH) was supposed to maintain a 1:1 exchange rate with ETH. However, during the waterfall, liquidity dried up, and the wBETH/ETH spot market experienced a 20% discount. The margin system then wrote down the wBETH collateral accordingly, triggering liquidations for positions that were effectively fully collateralized by the underlying ETH.
Automatic Deleveraging (ADL) Mechanism
When liquidations cannot be executed at the current market price, the exchange implements an automatic liquidation (ADL) mechanism to socialize losses among profitable traders. ADL forces profitable positions to be closed at the current price to offset the losses of liquidated positions.
During the October 2019 slump, Binance executed ADLs on multiple trading pairs. Traders holding profitable long positions saw their trades forcefully liquidated, not due to their own risk management failures, but rather because other traders’ positions became insolvent.
ADL reflects the underlying architectural choices of centralized derivatives trading: exchanges guarantee themselves against losses, so losses must be borne in the following ways:
- Insurance Fund (capital reserved by the exchange to cover liquidation losses)
- ADL (Forced Liquidation of Profitable Traders)
- Socialized loss (spreading the loss across all users)
The ratio of the insurance fund size to open interest determines the frequency of ADLs. In October 2025, Binance's insurance fund totaled approximately $2 billion. This provided 50% coverage relative to the $4 billion in open interest on BTC, ETH, and BNB perpetual contracts. However, during the October waterfall, total open interest across all trading pairs exceeded $20 billion, and the insurance fund was unable to cover shortfalls.
After the October 2018 crash, Binance announced that it would guarantee against ADLs when the total open interest in U-margined perpetual contracts for BTC, ETH, and BNB falls below $4 billion. While this policy enhances trust, it also exposes a structural contradiction: if the exchange wants to completely avoid ADLs, it must maintain a larger insurance fund, which would divert funds that could be used profitably.
On-chain failures: The limitations of blockchain protocols
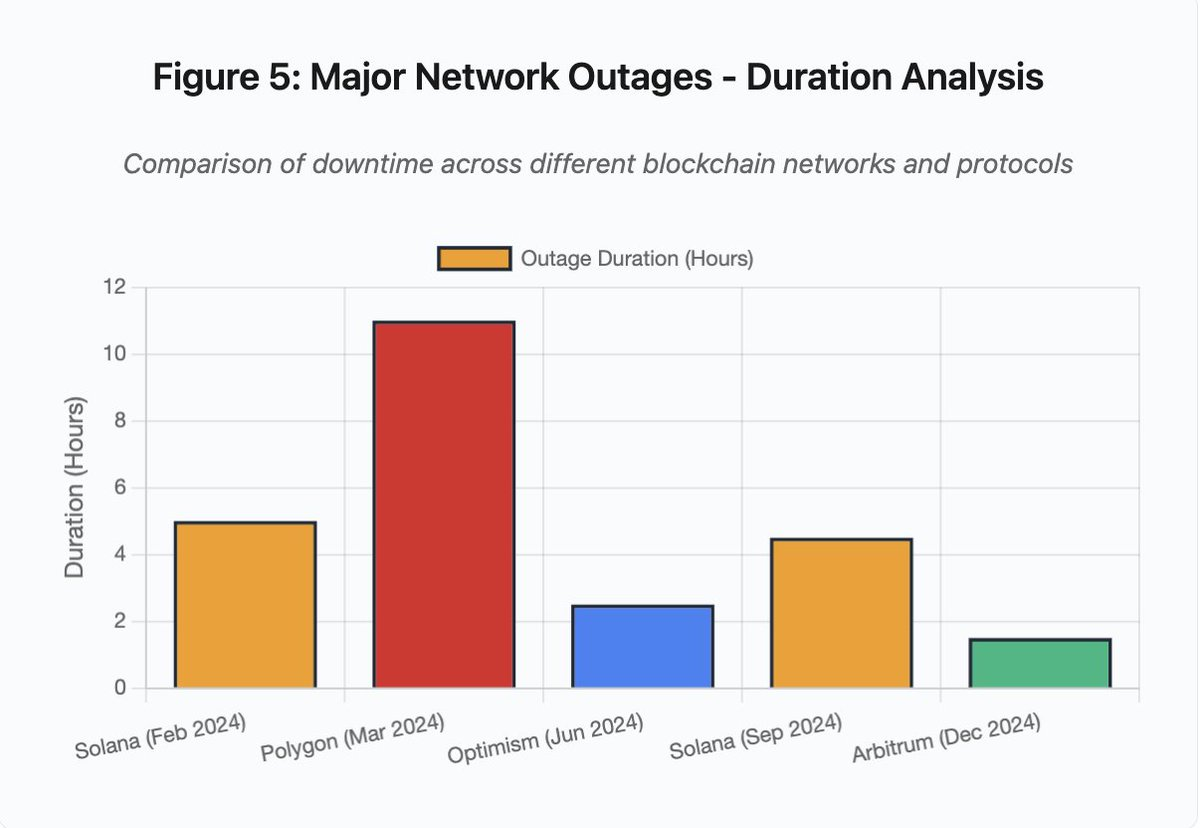
Figure 5: Major Network Outages - Duration Analysis
- Solana (February 2024): 5 hours - Voting throughput bottleneck
- Polygon (March 2024): 11 hours - Validator version mismatch
- Optimism (June 2024): 2.5 hours - Sequencer overload (airdrop)
- Solana (September 2024): 4.5 hours - spam attack
- Arbitrum (December 2024): 1.5 hours - RPC provider failure
Solana: Consensus Bottleneck
Solana experienced multiple outages between 2024 and 2025. The outage in February 2024 lasted approximately 5 hours, and the outage in September lasted 4-5 hours. These outages stemmed from a similar root cause: the network was unable to handle transaction volumes during spam attacks or extreme activity.
Solana's architecture is optimized for high throughput. Under ideal conditions, the network can process 3,000-5,000 transactions per second with sub-second finality. This performance is orders of magnitude higher than Ethereum. However, during stress events, this optimization can create vulnerabilities.
The September 2024 outage was caused by a flood of junk transactions that overwhelmed the validator voting mechanism. Solana's validators must vote on blocks to reach consensus. In normal operations, validators prioritize voting transactions to ensure consensus. However, the previous protocol treated voting transactions the same as regular transactions in the fee market.
When the transaction mempool fills up with millions of junk transactions, validators struggle to broadcast voting transactions. Without sufficient votes, blocks can't be finalized. Without finalized blocks, the chain stalls. Users' pending transactions become stuck in the mempool, preventing new transactions from being submitted.
The third-party monitoring tool StatusGator documented multiple Solana service outages in 2024 and 2025, but Solana officials haven't released a formal explanation. This creates information asymmetry, making it difficult for users to distinguish between personal connection issues and overall network problems. While third-party services provide oversight, the platform itself should maintain a comprehensive status page to establish transparency.
Ethereum: Gas Fee Explosion
Ethereum experienced extreme gas fee spikes during the 2021 DeFi boom. Simple transfers saw transaction fees exceeding $100, while complex smart contract interactions saw fees as high as $500-1000. This made the network nearly unusable for small transactions and created another attack vector: MEV (maximum extractable value) extraction.
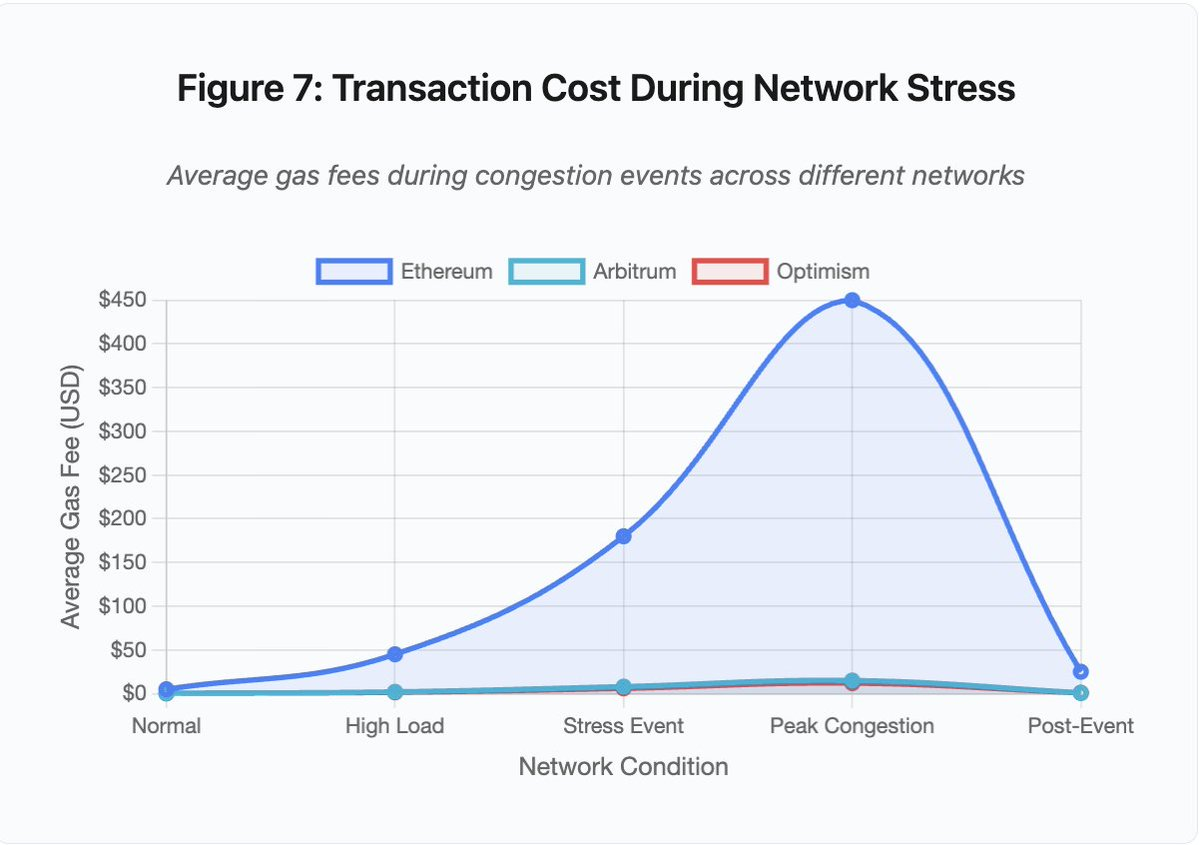
Figure 7: Transaction costs under network stress
- Ethereum: $5 (normal) → $450 (peak congestion) - a 90x increase
- Arbitrum: $0.50 → $15 – a 30x increase
- Optimism: $0.30 → $12 – 40x growth
In a high gas fee environment, MEV becomes a significant source of profit for validators. MEV refers to the additional revenue a validator earns by reordering, including, or excluding transactions. In this environment, arbitrageurs compete to front-load trades on large DEXs, while liquidation bots compete to be the first to liquidate undercollateralized positions. This competition leads to intensified gas fee bidding wars, with even lower-cost Layer 2 solutions experiencing significant fee increases due to high demand. High gas fee environments further amplify MEV profit opportunities, increasing the frequency and scale of related activities.
During periods of congestion, users who want to ensure their transactions are included must outbid the MEV bots. This creates a situation where transaction fees exceed the transaction value itself. Want to claim your $100 airdrop? Pay $150 in gas fees. Need to add collateral to avoid liquidation? Compete with bots that pay $500 for priority.
Ethereum's gas limit represents the total amount of computation that can be performed per block. During periods of congestion, users bid for scarce block space. The fee market operates as designed: the highest bidder wins. However, this design makes the network more expensive during peak usage periods, precisely when users need access the most.
Layer 2: Sorter Bottleneck
Layer 2 solutions attempt to address this problem by moving computation off-chain while inheriting Ethereum's security through periodic settlements. Optimism, Arbitrum, and other Rollups process thousands of transactions off-chain and then submit compressed proofs to Ethereum. This architecture successfully reduces the cost of individual transactions during normal operation.
But Layer 2 solutions introduce new bottlenecks. In June 2024, Optimism experienced an outage when 250,000 addresses simultaneously claimed an airdrop. The sorter, the component responsible for sorting transactions before submitting them to Ethereum, became overwhelmed. Users were unable to submit transactions for several hours.
The outage revealed that moving computation off-chain doesn't eliminate the need for infrastructure. Collators must process incoming transactions, sort them, execute them, and generate fraud proofs or zero-knowledge proofs for Ethereum settlements. Under extreme traffic, collators face the same scaling challenges as standalone blockchains.
Multiple RPC providers must be available. If the primary provider fails, users should be able to seamlessly switch to a backup. During the Optimism outage, some RPC providers remained operational, while others failed. Users whose wallets defaulted to the failed provider were unable to interact with the chain, even though the chain itself remained alive.
AWS outages repeatedly expose the risks of centralized infrastructure in the crypto ecosystem:
- October 20, 2025: US-EAST-1 region experiences outage, impacting Coinbase, Venmo, Robinhood, Chime, and others. AWS acknowledges increased error rates for DynamoDB and EC2 services.
- April 2025: Regional outage affects Binance, KuCoin, MEXC, and other exchanges on the same day. AWS hosting components of major exchanges fail.
- December 2021: The US-EAST-1 outage caused Coinbase, Binance.US, and the "decentralized" exchange dYdX to go down for 8-9 hours, while also affecting Amazon's own warehouses and major streaming services.
- March 2017: An S3 (Simple Storage Service) outage prevented users from accessing Coinbase and GDAX for five hours, triggering widespread internet outages.
These exchanges host critical components on AWS infrastructure. When AWS experiences a regional outage, multiple major exchanges and services become unavailable simultaneously. During the outage—precisely when market volatility might require immediate action—users are unable to access funds, execute trades, or modify positions.
Polygon: Consensus version mismatch
In March 2024, Polygon experienced an 11-hour outage due to a validator version inconsistency. This was the longest outage analyzed among major blockchain networks, highlighting the severity of the consensus failure. The root cause was that some validators were running an older version of the software while others had upgraded to a newer version. Because the two versions calculated state transitions differently, validators disagreed about the correct state, leading to a consensus failure.
The chain was unable to produce new blocks because validators could not agree on the validity of the blocks. This created a deadlock: validators running the old software rejected blocks from validators running the new software, and validators running the new software rejected blocks from the old software.
The solution requires coordinating validator upgrades. But coordinating upgrades during an outage takes time. Every validator operator must be contacted, the correct software version must be deployed, and their validators must be restarted. In a decentralized network with hundreds of independent validators, this coordination can take hours or even days.
Hard forks typically use a block height as a trigger. All validators complete the upgrade by a specific block height to ensure simultaneous activation. However, this requires advance coordination. Incremental upgrades, where validators gradually adopt the new version, carry the risk of version mismatches, as seen in the Polygon outage.
Architectural Trade-offs
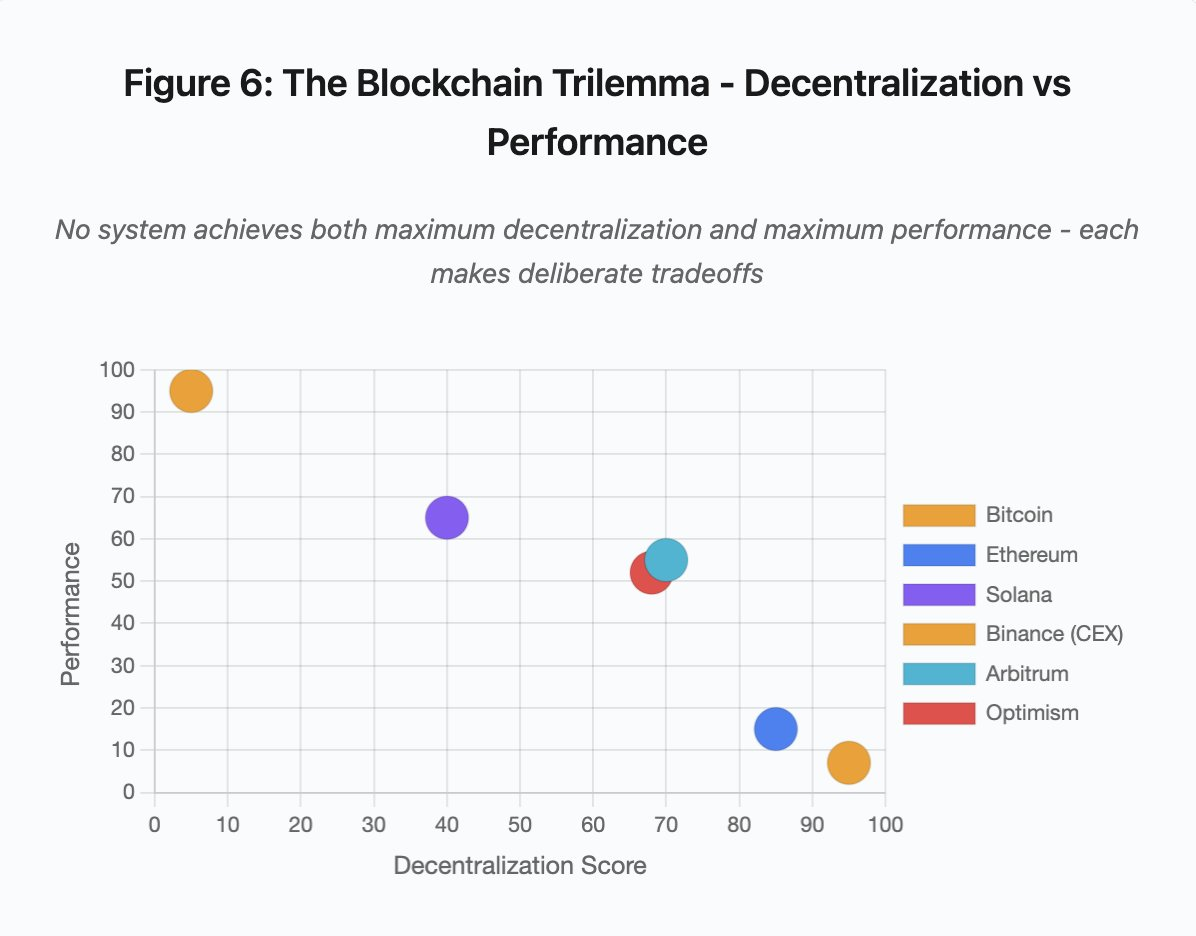
Figure 6: Blockchain Trilemma - Decentralization vs. Performance
The “Blockchain Trilemma” reflects the following system:
- Bitcoin: Highly decentralized, low performance
- Ethereum: Highly decentralized, moderately performant
- Solana: Moderately decentralized, high performance
- Binance (CEX): Minimum Decentralization, Maximum Performance
- Arbitrum/Optimism: Medium to high decentralization, medium performance
Core Insight: No system can achieve both maximum decentralization and highest performance. Each design makes deliberate trade-offs for different use cases.
Centralized exchanges achieve low latency through architectural simplicity. Matching engines process orders in microseconds, state resides in a centralized database, and there's no consensus protocol overhead. However, this simplicity also creates a single point of failure. When the infrastructure comes under stress, cascading failures can propagate through tightly coupled systems.
Decentralized protocols distribute state across validators, eliminating single points of failure. High-throughput chains maintain this property even during outages (funds are not lost, only liveness is temporarily impaired). However, reaching consensus among distributed validators introduces computational overhead. Validators must reach consensus before state transitions can be finalized. When validators are running incompatible versions or face overwhelming traffic, the consensus process can be temporarily halted.
Adding replicas improves fault tolerance but increases coordination costs. In a Byzantine fault-tolerant system, each additional validator increases communication overhead. High-throughput architectures minimize this overhead through optimized validator communication, achieving superior performance but also making them vulnerable to certain attack patterns. Security-focused architectures prioritize validator diversity and consensus robustness, limiting base layer throughput while maximizing resiliency.
Layer 2 solutions attempt to provide both of these characteristics through a layered design. They inherit Ethereum's security properties through L1 settlement while providing high throughput through off-chain computation. However, they introduce new bottlenecks at the sorter and RPC layers, demonstrating that while architectural complexity solves some problems, it also creates new failure modes.
Scalability remains a fundamental issue
These incidents reveal a recurring pattern: blockchains and transaction systems perform well under normal loads but often break down under extreme stress.
- Solana handled daily traffic effectively but collapsed when transaction volume increased by 10,000%.
- Ethereum 's gas fees remained reasonable before the popularity of DeFi applications, but then rose sharply due to congestion.
- Optimism ’s infrastructure operated smoothly under normal circumstances, but problems arose when 250,000 addresses simultaneously claimed the airdrop.
- Binance 's API functioned normally during normal trading, but was constrained by the surge in traffic during the liquidation wave. Specifically, during the October 2025 incident, Binance's API rate limits and database connectivity, which were sufficient during normal operations, became bottlenecks as traders adjusted their positions simultaneously during the liquidation wave. Furthermore, the forced liquidation mechanism designed to protect the exchange actually exacerbated the problem during the crisis, forcing a large number of users into selling positions at the worst possible moment.
Autoscaling is inadequate for sudden load surges, as it takes several minutes for new servers to come online. During this time, the margin system may mark positions based on erroneous price data generated by an illiquid order book. By the time the new servers come online, the chain reaction of liquidations has already spread.
Overprovisioning to handle rare stress events increases daily operational costs, so exchanges typically optimize their systems for typical loads and accept occasional failures as an economically sound option. However, this choice passes the cost of downtime on to users, who face liquidation issues, transaction freezes, or loss of access to funds during critical market fluctuations.
Infrastructure improvements
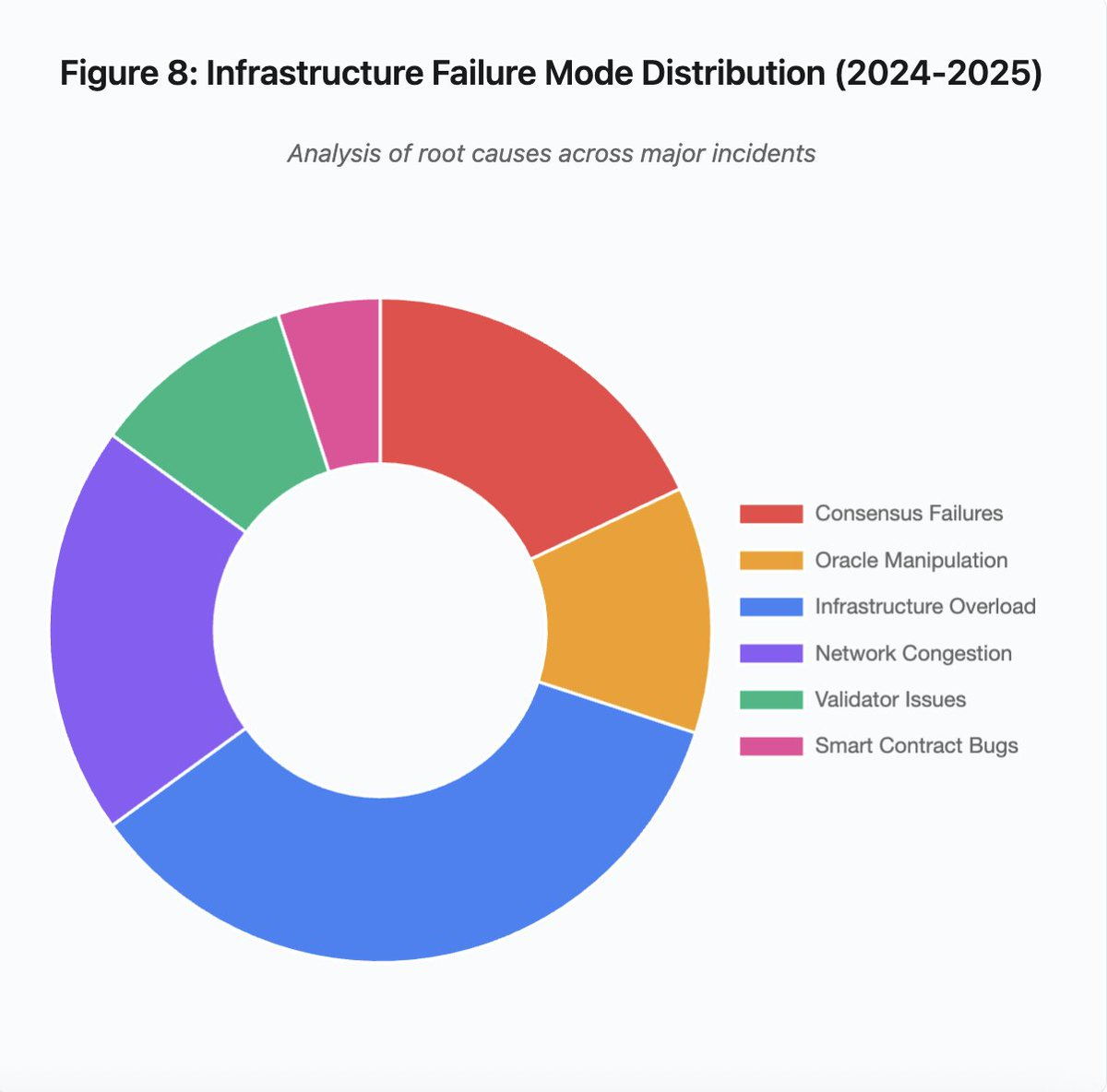
Figure 8: Infrastructure failure mode distribution (2024-2025)
The leading causes of infrastructure failures in 2024-2025 include:
- Infrastructure overload: 35% (most common)
- Network congestion: 20%
- Consensus failure: 18%
- Oracle manipulation: 12%
- Validator Issues: 10%
- Smart contract vulnerabilities: 5%
Several architectural improvements can be made to reduce the frequency and severity of failures, but each comes with trade-offs:
1. Separate pricing and clearing systems
The October incident stemmed in part from tying margin settlement to spot market prices. Using the wrapped asset exchange rate rather than the spot price would have avoided distorted wBETH valuations. More broadly, key risk management systems should not rely on potentially manipulated market data. Using independent oracles, multi-source aggregation, and TWAP calculations can provide more reliable prices.
2. Over-provisioning and redundant infrastructure
The AWS outage that affected Binance, KuCoin, and MEXC in April 2025 demonstrated the risks of centralized infrastructure dependency. Running critical components across multiple cloud providers increases operational complexity and costs, but eliminates dependency failures. Layer 2 networks can maintain multiple RPC providers with automatic failover. While the additional overhead may seem wasteful during normal operations, it can prevent hours of downtime during peak demand.
3. Strengthen stress testing and capacity planning
A system's "works well until it breaks" pattern indicates inadequate stress testing. Simulating 100x normal load should become standard practice. Identifying bottlenecks in development is much cheaper than discovering them during a real outage. However, realistic load testing remains challenging. Production traffic exhibits patterns that synthetic tests cannot fully capture. Users behave differently during a real outage than during testing.
The way forward
Blockchain systems have made significant technological advances, but they still face significant shortcomings when it comes to stress testing. Current systems rely on infrastructure designed for traditional business hours, while the crypto market operates globally and continuously. This means that when stress events occur outside of normal business hours, teams must urgently address the issues, and users can face significant losses. Traditional markets suspend trading under stressful conditions, while crypto markets simply implement circuit breakers. Whether this is a system feature or a flaw depends on one's perspective and perspective.
Overprovisioning is a reliable solution to the problem, but it conflicts with economic incentives. Maintaining excess capacity is expensive and only applies to rare events. Unless the cost of a catastrophic failure is high enough, the industry may not take proactive action.
Regulatory pressure could be a driving force for change, such as requiring 99.9% uptime or limiting acceptable downtime. However, regulation often emerges after a disaster, as in the case of Mt. Gox's 2014 collapse, which prompted Japan to formally regulate cryptocurrency exchanges. The chain reaction in October 2025 is expected to trigger similar regulatory responses, though whether these responses will mandate outcomes (such as maximum acceptable downtime, maximum slippage during liquidations) or implementation methods (such as specific oracle providers, circuit breaker thresholds) remains uncertain.
The industry needs to prioritize system robustness over growth during a bull market. While downtime issues are often overlooked during market booms, stress testing during the next cycle could expose new vulnerabilities. Whether the industry will learn from the events of October 2025 or repeat the same mistakes remains an open question. History shows that the industry often discovers critical vulnerabilities through multi-billion dollar failures rather than proactively improving systems. For blockchain systems to maintain reliability under pressure, they need to move from prototype architectures to production-grade infrastructure, which requires not only funding but also a balance between development speed and robustness.






