
By Mario Chow & Figo @IOSG
introduction
Over the past 12 months, the relationship between web browsers and automation has shifted dramatically. Nearly every major tech company is scrambling to build autonomous browser agents. This trend has intensified since the end of 2024: OpenAI launched Agent mode in January, Anthropic released a "computer usage" feature for the Claude model, Google DeepMind launched Project Mariner, Opera announced its agent-based browser Neon, and Perplexity AI launched the Comet browser. The signal is clear: the future of AI lies in agents that can autonomously navigate the web.
This trend isn't just about adding smarter chatbots to browsers; it's about a fundamental shift in how machines interact with digital environments. Browser agents are AI systems that can "see" web pages and take actions: click links, fill out forms, scroll, enter text—just like a human user. This model promises to unlock enormous productivity and economic value by automating tasks that currently require manual intervention or are too complex to perform with traditional scripts.
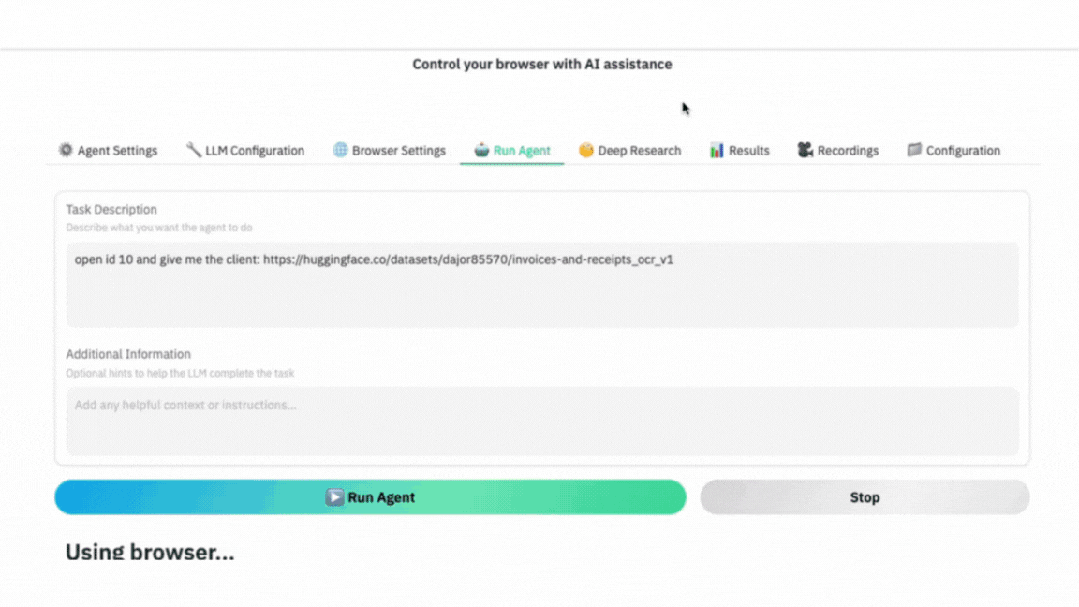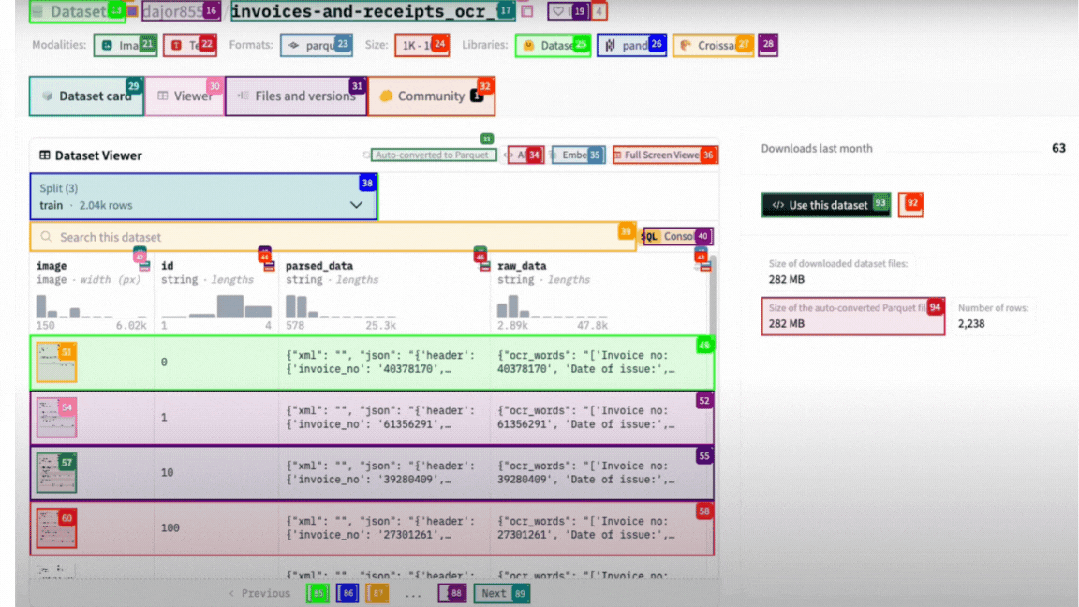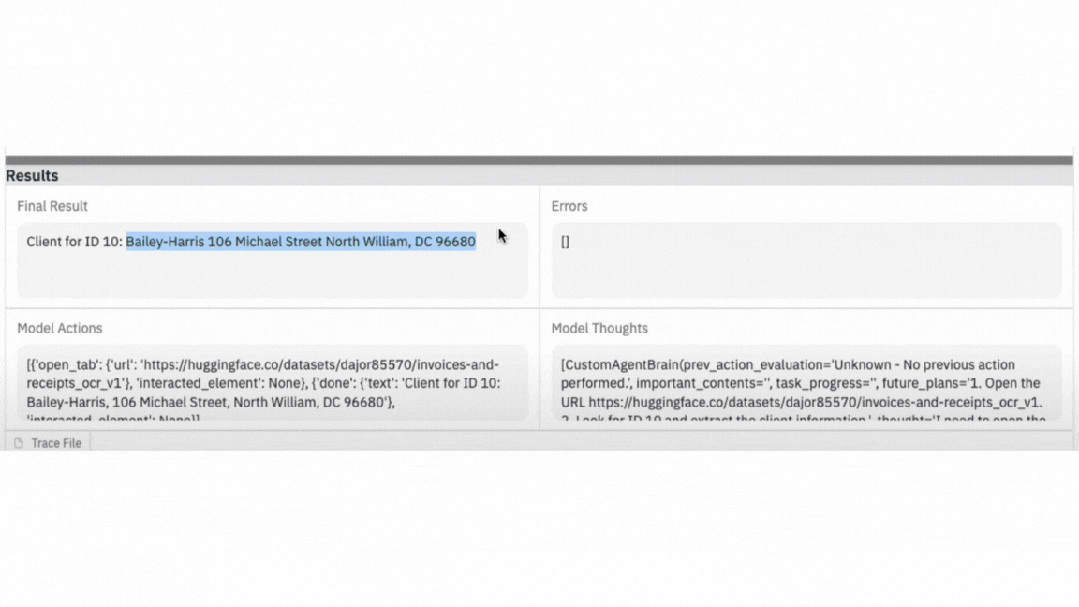
▲ GIF demonstration: The actual operation of the AI browser agent: following instructions, navigating to the target dataset page, automatically taking screenshots and extracting the required data.
Who will win the AI browser war?
Almost all major tech companies (and some startups) are developing their own browser AI agents. Here are some of the most representative projects:
OpenAI – Agent Mode
OpenAI's Agent mode (formerly known as Operator, launched in January 2025) is an AI agent with its own browser. Operator can handle a variety of repetitive online tasks: such as filling out web forms, ordering groceries, and scheduling meetings: all completed through the standard web interface commonly used by humans.
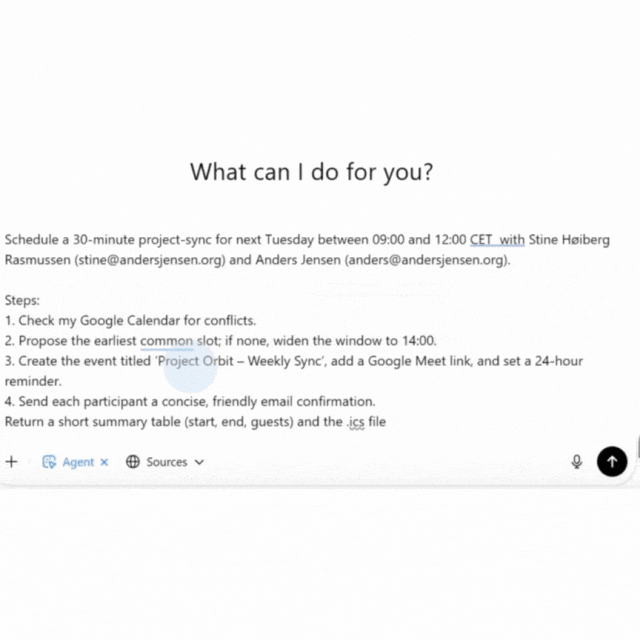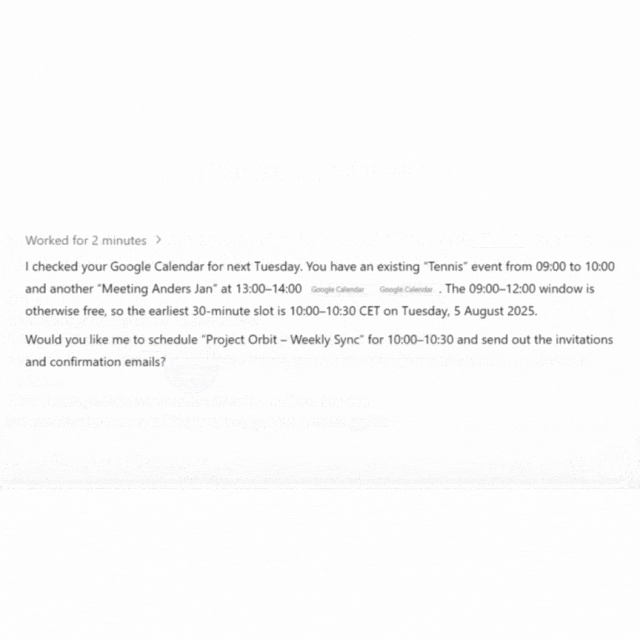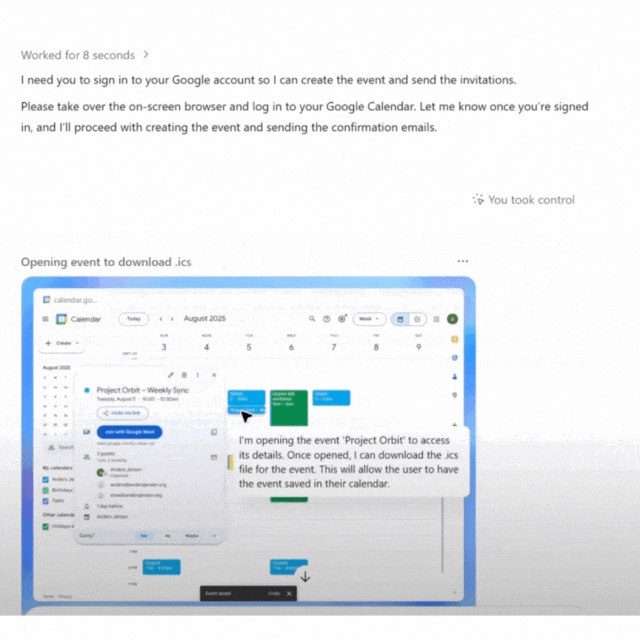
The AI agent schedules meetings like a professional assistant: checks the calendar, finds available time slots, creates the event, sends confirmations, and generates the .ics file for you.
Anthropic – “Computer Use” by Claude
At the end of 2024, Anthropic introduced a new "Computer Use" feature in Claude 3.5, giving it the ability to operate computers and browsers like a human. Claude can view the screen, move the cursor, click buttons, and enter text. This is the first large-scale proxy tool of its kind to enter public beta, allowing developers to enable Claude to automatically navigate websites and applications. Anthropic is positioning this as an experimental feature, primarily aimed at automating multi-step workflows on the web.
Perplexity – Comet
AI startup Perplexity (known for its question-answering engine) launched the Comet browser as an AI-powered alternative to Chrome in mid-2025. The core of Comet is a conversational AI search engine built into the address bar (omnibox), which can provide instant questions and answers and summaries instead of traditional search links.
- In addition, Comet also comes with Comet Assistant, a sidebar-resident agent that automates routine tasks across websites. For example, it can summarize your open emails, schedule meetings, manage browser tabs, or browse and crawl the web on your behalf.
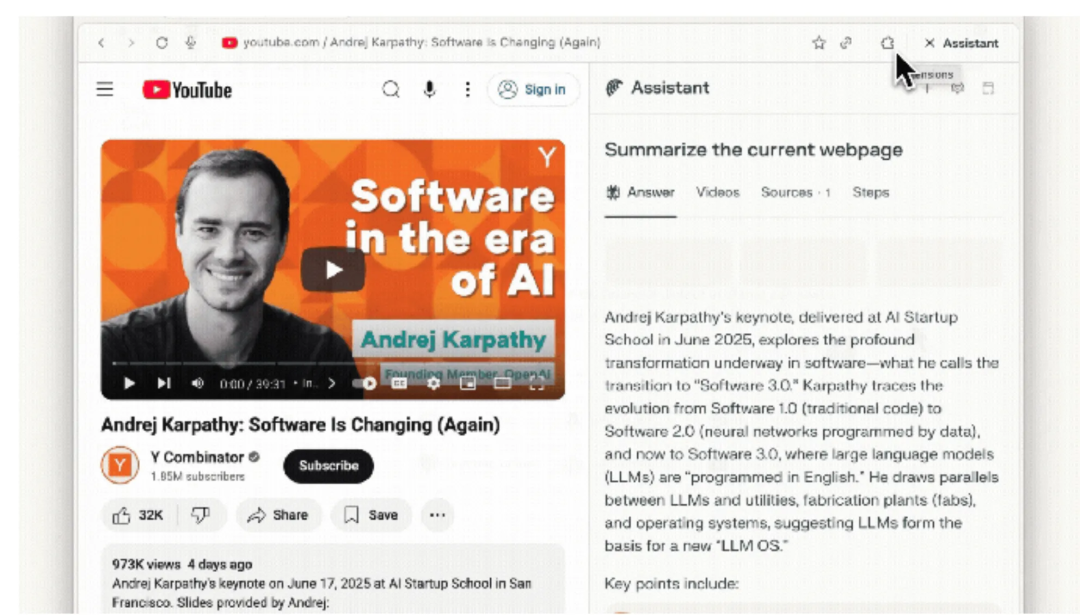
- By making the agent aware of the current web page content through a sidebar interface, Comet aims to seamlessly integrate browsing with AI assistants.
Real-world application scenarios of browser proxies
Earlier, we reviewed how major tech companies (OpenAI, Anthropic, Perplexity, and others) have embedded functionality into browser agents through various product forms. To better understand their value, let's examine how these capabilities are being applied in real-world scenarios, both in daily life and in enterprise workflows.
Daily web automation
#E-commerce and personal shopping
One very practical scenario is to delegate shopping and ordering tasks to an agent. The agent can automatically fill your online shopping cart and place orders based on a fixed list, or search for the lowest price across multiple retailers and complete the checkout process on your behalf.
For travel, you could ask an AI to perform a task like, "Book me a flight to Tokyo next month for under $800 and a hotel with free Wi-Fi." The agent would handle the entire process: searching for flights, comparing options, filling out passenger information, and completing the hotel reservation, all through the airline and hotel websites. This level of automation goes far beyond existing travel bots: it goes beyond making recommendations and directly executes the purchase.
#Improve office efficiency
Agents can automate many repetitive business operations that people perform in a browser. For example, organizing emails and extracting to-do items, or checking for availability in multiple calendars and automatically scheduling meetings. Perplexity's Comet assistant can already summarize the contents of your inbox or add schedules for you through a web interface. With your authorization, agents can also log in to SaaS tools to generate regular reports, update spreadsheets, or submit forms. Imagine an HR agent that can automatically log in to different recruitment websites to post positions; or a sales agent that can update lead data in a CRM system. These daily trivial tasks would have consumed a lot of employee time, but AI can complete them by automating web forms and page operations.
Beyond single tasks, agents can orchestrate complete workflows across multiple networked systems. Each of these steps requires access to distinct web interfaces, which is exactly where browser agents excel. Agents can log into various dashboards for troubleshooting and even orchestrate processes, such as onboarding new employees (creating accounts across multiple SaaS websites). Essentially, any multi-step process that currently requires multiple website visits can now be performed by agents.
Current challenges and limitations
Despite their enormous potential, today's browser proxies are still far from perfect. Current implementations reveal several long-standing technical and infrastructure challenges:
Architecture mismatch
The modern web was designed for human-operated browsers and has evolved over time to actively resist automation. Data is often buried in HTML/CSS optimized for visual presentation, limited by interaction gestures (mouseover, swipe), or accessible only through undocumented APIs.
On top of this, anti-scraping and anti-fraud systems have artificially added additional barriers. These tools combine IP reputation, browser fingerprinting, JavaScript challenge responses, and behavioral analysis (e.g., mouse movement randomness, typing rhythm, dwell time). Paradoxically, the more "perfect" and efficient an AI agent appears—for example, filling out forms instantly and without error—the easier it is to identify as malicious automation. This can lead to hard failures: for example, an OpenAI or Google agent might successfully complete all the steps before checkout, only to be stopped by a CAPTCHA or secondary security filter.
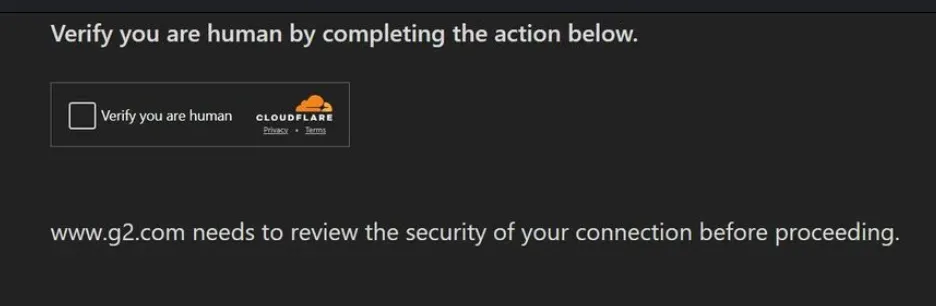
The combination of a human-optimized interface and a layer of bot-unfriendly defenses forces agents to adopt a fragile “human-robot mimicry” strategy, which is highly susceptible to failure and has a low success rate (less than one-third of completed transactions are completed without human intervention).
Trust and security concerns
For an agent to gain full control, it often requires access to sensitive information: login credentials, cookies, two-factor authentication tokens, and even payment information. This raises understandable concerns for both users and businesses:
- What if the proxy makes a mistake or is tricked by a malicious website?
- If an agent agrees to a certain terms of service or executes a certain transaction, who is responsible?
Based on these risks, the current system generally adopts a cautious approach:
- Rather than entering credit card information or agreeing to terms of service, Google's Mariner hands it back to the user.
- OpenAI's Operator prompts the user to take over a login or CAPTCHA challenge.

Anthropic's Claude-driven agent may simply deny logins, citing security concerns.
The result: frequent pauses and handoffs between AI and humans that diminish the experience of seamless automation.
Despite these obstacles, progress continues apace. Companies like OpenAI, Google, and Anthropic are learning from their failures with each iteration. As demand grows, a kind of "co-evolution" is likely to occur: websites become more friendly to agents in favorable scenarios, and agents will continue to improve their ability to mimic human behavior, bypassing existing barriers.
Methods and opportunities
Today's browser proxies face two distinct realities: on the one hand, the hostile environment of Web2, where anti-scraping and security measures are ubiquitous; on the other hand, the open environment of Web3, where automation is often encouraged. This difference determines the direction of various solutions.
The following solutions can be broadly divided into two categories: those that help proxies circumvent the hostile environment of Web2, and those that are native to Web3.
While browser proxies face significant challenges, new projects are emerging that attempt to address them directly. The cryptocurrency and decentralized finance (DeFi) ecosystems are becoming a natural testing ground, as they are open, programmable, and less hostile to automation. Open APIs, smart contracts, and on-chain transparency eliminate many common friction points in the Web2 world.
There are four categories of solutions, each addressing one or more of today’s core limitations:
Native proxy browser for on-chain operations
These browsers are designed from the ground up to be driven by autonomous agents and are deeply integrated with blockchain protocols. Unlike traditional Chrome browsers, which rely on Selenium, Playwright, or wallet plugins to automate on-chain operations, native proxy browsers directly provide APIs and trusted execution paths for agents to call.
In decentralized finance, transaction validity relies on cryptographic signatures, not on user "human-likeness." Therefore, in an on-chain environment, proxies can bypass the CAPTCHAs, fraud detection scores, and device fingerprinting checks common in the Web2 world. However, if these browsers are directed to Web2 websites like Amazon, they cannot bypass these defenses; in that scenario, standard anti-bot measures will still be triggered.
The value of a proxy browser is not that it can magically access all websites, but that:
- Native blockchain integration: Built-in wallet and signature support, no more need to go through MetaMask pop-ups or parse the DOM on the dApp frontend.
- Automation-first design: Provides stable high-level instructions that can be directly mapped to protocol operations.
- Security model: refined permission control and sandboxing ensure the security of private keys during the automation process.
- Performance optimization: Ability to execute multiple on-chain calls in parallel without browser rendering or UI delays.
#Case Study: Donut
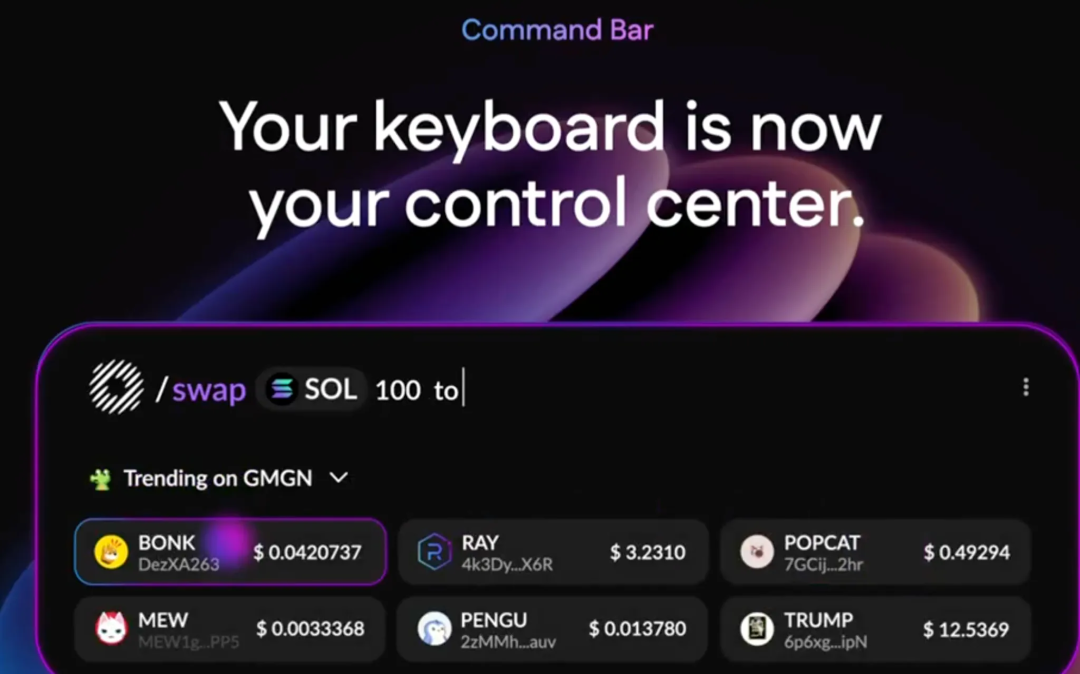
Donut integrates blockchain data and operations as first-class citizens. Users (or their agents) can hover to view real-time risk indicators for tokens or directly enter natural language commands like "/swap 100 USDC to SOL." By bypassing the adversarial friction points of Web2, Donut enables agents to operate at full speed in DeFi, improving liquidity, arbitrage, and market efficiency.
Verifiable and trusted proxy execution
Allowing agents to gain sensitive permissions is risky. Solutions like Trusted Execution Environments (TEEs) or Zero-Knowledge Proofs (ZKPs) can cryptographically confirm the expected behavior of an agent before execution, allowing users and counterparties to verify agent actions without exposing private keys or credentials.
#Case Study: Phala Network
Phala uses TEEs (such as Intel SGX) to isolate and protect the execution environment, preventing Phala operators or attackers from snooping or tampering with proxy logic and data. The TEE acts like a hardware-backed "safe room," ensuring confidentiality (invisible to the outside world) and integrity (unable to modify from the outside).
For browser proxies, this means they can log in, hold session tokens, or process payment information, without ever leaving the secure environment. Even if the user's machine, operating system, or network is compromised, this sensitive data cannot be leaked. This directly alleviates one of the biggest obstacles to proxy adoption: the trust issue with sensitive credentials and operations.
Decentralized structured data network
Modern anti-bot detection systems not only check if requests are "too fast" or "automated," but also combine IP reputation, browser fingerprinting, JavaScript challenge responses, and behavioral analysis (e.g., cursor movement, typing rhythm, session history). Proxies originating from data center IPs or from a completely repeatable browsing environment are easily identified.
To address this issue, these networks no longer crawl web pages optimized for humans, but instead directly collect and provide machine-readable data, or proxy traffic through real human browsing environments. This approach bypasses the vulnerabilities of traditional crawlers in parsing and anti-crawling, providing cleaner and more reliable input for proxies.
By proxying traffic to these real-world sessions, the distribution network allows AI agents to access web content like humans, without immediately triggering a block.
#Case
- Grass: A decentralized data/DePIN network where users share unused residential broadband, providing agent-friendly, geographically diverse access to public web data for collection and model training.
- WootzApp: An open-source mobile browser that supports cryptocurrency payments, has a backend proxy, and offers zero-knowledge identity. It gamifies AI/data tasks for consumers.
- Sixpence: A distributed browser network that routes traffic for AI agents through browsing by contributors worldwide.
However, this isn't a complete solution. Behavioral detection (mouse/scroll tracking), account-level restrictions (KYC, account age), and fingerprint consistency checks can still trigger blockages. Therefore, distributed networks are best viewed as a foundational privacy layer that must be combined with human-like execution strategies to be most effective.
Web Standards for Proxy (Forward-Looking)
Currently, more and more technical communities and organizations are exploring: If future Internet users are not only humans but also automated agents, how can websites deal with them safely and compliantly?
This has prompted discussions on some emerging standards and mechanisms, with the goal of allowing websites to explicitly state "I allow trusted proxies to access" and provide a secure channel to complete the interaction, rather than blocking proxies as "robot attacks" by default as they do today.
- "Agent Allowed" tag: Just like robots.txt, which search engines follow, web pages might add a tag to their code to tell browser agents that "this is safe to access." For example, if you use an agent to book a flight, the website won't display a bunch of CAPTCHAs, but will instead provide a direct, authenticated interface.
- API Gateway for Certified Agents: Websites can open a dedicated entrance for verified agents, like a "fast lane." Agents do not need to simulate human clicks and input, but instead use a more stable API path to complete orders, payments, or data queries.
- W3C Discussion: The World Wide Web Consortium (W3C) is already working on developing standardized pathways for "managed automation." This means that in the future, we may have a set of globally accepted rules that allow trusted proxies to be identified and accepted by websites while maintaining security and accountability.
While these explorations are still in their early stages, once implemented, they could significantly improve the relationship between humans, agents, and websites. Imagine this: no longer would agents have to desperately mimic human mouse movements to "fool" risk control, but instead could complete their tasks openly through an "officially approved" channel.
Crypto-native infrastructure will likely take the lead in this direction. This is because on-chain applications inherently rely on open APIs and smart contracts, making them ideal for automation. In contrast, traditional Web2 platforms, especially those relying on advertising or anti-fraud systems, will likely remain cautious and defensive. However, as users and businesses gradually embrace the efficiency gains brought by automation, these standardization efforts will likely become a key catalyst in driving the entire internet towards an agent-first architecture.
in conclusion
Browser agents are evolving from simple conversational tools to autonomous systems capable of completing complex online workflows. This shift reflects a broader trend toward embedding automation directly into the core interfaces users interact with the internet. While the potential for productivity gains is enormous, challenges are equally significant, including overcoming entrenched anti-bot mechanisms and ensuring safety, trust, and responsible use.
In the short term, improved agent reasoning capabilities, faster speeds, tighter integration with existing services, and advances in distributed networks are likely to gradually improve reliability. In the long term, we may see the gradual implementation of "agent-friendly" standards in scenarios where automation benefits both service providers and users. However, this transition will be uneven: adoption will be faster in automation-friendly environments like DeFi, while acceptance will be slower in Web2 platforms that rely heavily on user interaction and control.
In the future, competition among tech companies will increasingly center around how well their agents navigate real-world constraints, how securely they can be integrated into critical workflows, and how reliably they can deliver results in diverse online environments. Whether this ultimately reshapes the "browser wars" will depend not on pure technological prowess but on whether they can build trust, align incentives, and demonstrate tangible value in everyday use.






